11장 - 변수 이름의 기능
Edited by / 임수형 (sulogc)

11-1 좋은 이름을 위한 고려 사항
중요한 고려 사항
변수 이름은 그 자체로 변수가 되기때문에 그 이름이 변수가 나타내는 것을 완전하고 정확하게 설명하는지 중요하다.
- 변수가 표현하는 것을 단어로 서술.
- 서술문 자체가 좋은 변수인 경우가 있음.
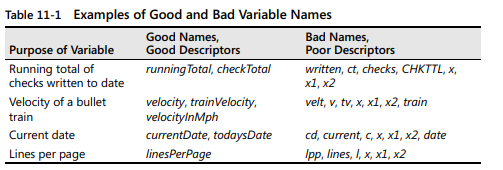
- 이름은 가능한한 구체적이어야 한다.
- 막연한 이름은 많은 정보를 제공하지도 않고 일반적으로 나쁜 이름이다.
문제 지향
좋은 이름은 어떻게 보다 무엇을 표현하는 경향이 있다. 문제 자체를 가리키는 이름을 사용하도록 한다.
- 직원 데이터 : inputRec -> employeeData
- 프린터 상태 : bitFlag -> printerReady
최적의 이름 길이
너무 긴 이름은 입력하기 어렵고 프로그램의 외관상 구조를 모호하게 할 수 있다. 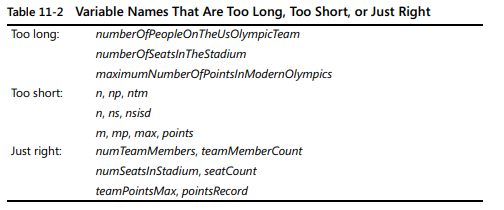
- 10~16자 사이의 길이 등의 가이드는 반드시 지켜야한다는 게 아니라, 짧은 이름이 많다면 이름이 분명하게 작성되었는지 확인해 보아야 한다는 뜻이다.
범위가 변수명에 미치는 효과
W. J. 한센의 연구에서 긴 이름은 거의 사용하지 않는 변수나 전역 변수에 좋고 짧은 이름은 지역 변수나 반복문 변수에 좋다는 것을 발견했다. 전역 네임스페이스에 있는 변수에는 한정자(qualifier)를 사용하라. 자바에서는 패키지를 사용하여 같은 효과를 얻을 수 있다. 지원이 안되는 언어에서도 전역 공간을 분할하기 위해 서브 시스템 연상 기호를 접두사로 사용하는 등 이름 규칙을 사용할 수 있다. (uiEmployee)
변수 이름의 계산값 한정자
총계, 평균, 최댓값 등 계산된 값을 보관하는 변수의 경우, 접미사로 한정자를 붙이자. 혼란을 막고, 일관성을 제공한다.
Sum, Average, Max, Min, Record, String, Pointer
일반적인 변수명의 반의어
반의어를 정확하게 사용하라. 일관성을 유지하고 가독성을 높이는 데 도움이 된다.
begin/end
first/last
locked/unlocked
min/max
...
11-2 특정 타입의 데이터 이름 짓기
데이터 이름을 지을 때 일반적 고려 사항과 더불어 데이터 종류에 따른 고려 사항이 있다. 반복문, 상태 변수, 임시 변수, 불린 변수, 열거형, 이름 상수
반복문 인덱스 이름
반복문은 컴퓨터 프로그래밍에서 일반적이고 관습적으로 i, j, k를 사용한다.
for ( i = firstItem; i < lastItem; i++) {
data[i] = 0;
}
변수를 반복문 외부에서 사용하거나, 반복문이 길어진다면, i가 무엇을 나타내는지 쉽게 이름을 짓는 게 좋다.
상태 변수 이름
상태 변수는 프로그램의 상태를 설명한다. 플래그라는 이름은 그것이 무엇을 하는지 아무런 단서도 제공하지 않기 때문에 변수 이름에서 사용하지 말아야 한다.
flag = 0x1;
statusFlag = 0x80;
printFlag = 16;
computeFlag = 0;
dataReady = true;
characterType = CONTTROL_CHARACTER;
reportType = ReportType_Annual;
recalcNeeded = false;
코드는 밝혀내야 할 대상이 아니다. 코드는 직관적으로 이해할 수 있어야 한다.
임시 변수 이름
대개는 temp, x 등 모호하고 이해하기 어려운 이름을 갖는다. ‘임시’ 상태이기 때문에 별생각 없이 다루게 되어 오류가 발생할 가능성이 커진다. 임시 변수를 조심하라 변수의 값을 일시적으로 보관할 필요가 종종 있다. 하지만 그렇게 생각하면 프로그램에 있는 거의 모든 변수가 임시 변수다.
temp = sqrt( b^2 - 4*a*c );
root[0] = ( -b + temp ) / ( 2*a );
// 판별식 discriminant
discriminant = sqrt( b^2 - 4*a*c );
root[0] = ( -b + discriminant ) / ( 2*a );
불린 변수 이름
- 전형적인 불린 변수의 이름을 기억
done - 수행 여부 error - 오류 발생 여부 found - 발견 여부 success, ok - 연산 성공 여부 참이나 거짓의 의미를 함축하는 불린 변수의 이름을 사용 status를 error, statusOK와 같은 이름으로 대체하자.
- 긍정적인 불린 변수 이름을 사용 부정적 이름은 부정이 된 경우, 이중 부정이 되어 이해하기가 어렵다.
if not notFound
열거형의 이름
열거형을 사용하면 Color_, Planet_과 같은 접두사를 사용하여 해당 타입의 맴버가 모두 같은 그룹에 속한다는 것을 보장할 수 있다.
상수 이름
상수 이름은 상수가 가리키는 숫자보다는 상수가 표현하는 추상적인 대상을 나타내야 한다.
FIVE=6.0
DONUTS_MAX=5.0
11-3 이름 규약의 효과
규약이 왜 필요한가?
- 일관성
- 다른 프로젝트에서의 빠른 파악
- 개발 혼란성 낮춤
- 규약에 의해 지역, 클래스, 전역 데이터간 구분
- 관련 항목 사이의 관계 강조
언제 이름 규약이 필요한가?
- 여러 개발자의 공동작업
- 변경이나 유지보수 때문에 프로젝트 이관
- 프로그램의 수명이 긴 경우
- 특이한 용어가 많은 경우
11-4 비형식적인 이름 규약
개발 언어에 독립적인 규약을 위한 가이드라인
- 변수의 이름과 루틴의 이름을 구별
- 클래스와 객체를 구별

- 외형상 차이가 적고 대소문자를 구분하는 언어가 있는 경우 일관성이 보장되지 않는다.
- 1과 같은 이유.
- 보기 싫어서 잘 안 쓴다.
- 클래스 이름을 하나만 사용하는 대신 클래스의 모든 인스턴스 이름을 변경해야 될 수 있다.
- 변수에 대해서 더 많이 생각해야 하지만, 구체적이기 때문에 더 읽기 쉬운 코드가 된다.
- 전역 변수를 식별한다.
- 맴버 변수를 식별한다.
- 타입 선언을 식별한다.
- 이름 상수를 식별한다.
- 열거형의 요소를 식별한다.
- 입력만 하는 매개변수를 지정할 수 없는 언어에서는 이를 식별한다.
- 가독성을 위해 이름에 서식을 지정한다.
11-5 표준 접두사
공통적인 의미를 위한 접두사를 표준화하면 데이터 이름에 대해 간결하면서도 일관성 있고 읽기 쉬운 접근 방법을 제공할 수 있다.
표준 접두사는 사용자 정의형(User-Defined Type, UDT) 축약어와 의미적 접두사로 구성된다.
사용자 정의형
UDT 축약어는 이름이 있는 객체나 변수의 데이터형을 나타낸다.
의미적 접두사
의미적 접두사는 UDT보다 한 단계 더 나아가 변수나 객체가 어떻게 사용되는지 설명한다. 
표준 접두사의 장점
표준 접두사는 이름 규약이 갖는 장점 외에 다양한 장점을 제공한다.
- 모호해지기 쉬운 이름 영역을 정확하게 만든다.
- 이름을 더욱 간결하게 만든다.
totalParagraphs->cpaindexparagraphs->ipa - 추상 데이터형을 사용할 때 타입을 정확하게 검사할 수 있다. 표준 접두사의 문제는 개발자가 접두사에 이어지는 변수에 의미 있는 이름을 부여하지 않을 때 발생한다.
11-6 읽기 쉬운 짦은 이름
일반적인 축약어 가이드라인

축약어이 대한 의견
- 단어에서 한 문자를 없애는 방법으로 축약하지 않는다.
- 일관성 있게 축약한다.
- 발음할 수 있는 이름을 만든다.
- 잘못된 발음을 유발할 수 있는 조합을 피한다.
- 이름 충돌을 해결하기 위해서 유의어 사전을 사용한다.
- 매우 짧은 이름은 코드 내 변환 테이블을 사용하여 문서화한다.
- 모든 축약어를 프로젝트 수준의 “표준 축약어” 문서에 기록한다.
일정 규모는 주석으로 작성해도 괜찮지만, 대형 프로젝트에서 문서화하여 축약어의 위험성은 낮출 수 있다. 6개월 동안 쳐다보지 않은 코드 내 변수, 중복 축약어 생성, 편의성 증가...
11-7 피해야 할 변수 이름
- 오해의 소지가 있는 이름이나 축약어를 피한다.
- 유사한 의미가 있는 이름을 피한다.
- 이름은 유사하지만 의미가 다른 변수를 피한다.
- 이름에 숫자를 넣는 것을 피한다. (고유하게 포함 될 가능성)
- 대소문자만으로 변수의 이름을 구분하지 않는다.
- 표준 데이터형과 변수, 루틴의 이름은 사용하지 않는다.