12장 - 기본 데이터형
Edited by / (frog-slayer)

기본 자료형은 다른 모든 자료형을 만들기 위해 필요한, 가장 기초적인 빌딩 블럭이다.
12.1 Numbers in General
- “매직 넘버”는 피해라
- 프로그램 중에 아무런 설명없이 리터럴(literal) 수를 매직 넘버라 한다. 만약 사용 중인 언어가 이름 있는 상수(named constant)를 지원하면, 그걸 대신 쓰고, 그렇지 않으면 차라리 전역 변수를 사용해야 한다.
- 매직 넘버를 사용하지 않으면 얻을 수 있는 이점들
- 1) 신뢰성 있는 수정이 가능해진다.
- 2) 수정이 좀 더 쉬워진다.
- 3) 코드 가독성이 좋아진다.
- 필요하다면 하드 코딩된 0, 1은 사용해도 좋다
- 프로그램 내의 리터럴은 0, 1만 있는 게 좋고, 나머지 모든 리터럴은 그게 뭔지 설명할 수 있는 것으로 대체하는 게 좋다.
- 0으로 나누기 오류가 일어날 수 있을지 예상해라
- 나눗셈의 경우, 0으로 나누게 되는 경우가 있는지 확인하고, 만약 그렇다면 0으로 나누기 오류를 방지하는 코드를 써야 한다.
- 형 변환을 좀 더 명확하게 해라
- 자료형이 섞인 비교는 피해라
- 컴파일러 경고에 주의를 기울여라
12.2 Integers
- 정수 나눗셈을 확인하자
- 언어마다 다르기는 하지만, 7/10은 0.7이 아닐 수 있다.
- 정수 오버플로를 확인
- 정수 곱, 또는 합을 계산하는 경우, 오버플로를 방지하는 가장 쉬운 방법은 수식의 각 항에서 정수 최댓값을 염두에 두는 것이다.
- 프로그램의 확장성도 생각하자. 프로그램이 확장됨에 따라 사용 중이던 자료형을 확장해야 되는 경우가 발생할 수도 있다.
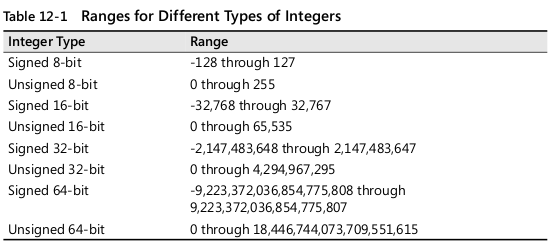
- 중간 계산 결과에서도 오버플로를 확인해야 한다
- 계산 도중에 발생할 수 있는 오버플로 방지를 위해서는, 보다 큰 정수 자료형이나 부동 소수점 자료형을 사용할 수 있다.
12.3 Floating-Point Numbers
대부분의 소수는 0과 1로 나타내기 어렵기 때문에, 부동 소수점 수를 사용하더라도 오차는 발생하게 된다.
- 크기가 서로 너무 다른 수끼리의 덧셈/뺄셈은 삼가라
- 32비트 부동 소수점 변수를 사용하는 경우, $1,000,000.00 + 0.1$은 $1,000.000.1$이 아니라 $1,000,000,00$이 될 수도 있다.
- 이러한 오차를 최대한 피하기 위한 방법으로는, 주어진 수들을 크기 순으로 정렬하고 작은 수부터 차례로 계산하는 방법이 있다.
- 동일 비교는 어렵다
- 수학적으로는 같은 수라도 그 수까지로 이르는 과정에 차이가 있으면 다른 수로 판단하게 될 수도 있다.
- 어느 정도의 오차(epsilon, 혹은 delta)를 정하고, 주어진 두 수의 차가 그 이하라면 같은 수로 판정하는 방법을 사용한다.
- 하드코딩된 값을 사용해도 되지만, 애플리케이션에 따라 따로 계산을 해서 사용해야하는 경우도 있을 것이다.
- 반올림 오류를 예상해라
- 좀 더 정밀도가 높은 자료형 사용하기: 단정밀도를 사용했다면 배정밀도를 사용
- BCD 사용하기: 더 느리고 크지만 반올림 오류는 덜 일어남. 정밀도가 특히 중요한 경우에는 쓰는 게 좋다.
- 부동 소수점 자료형을 정수형으로 변환해서 사용: 1.99 달러 대신, 199센트로 생각하기
- 특정 자료형에 대한 언어와 라이브러리 지원 확인하기
- 어떤 언어의 경우 반올림 오류에 대응하기 위한 특정 자료형을 지원하기도 함
12.4 Characters and Strings
- 매직 캐릭터, 스트링은 피해라
- 문자열 정보는 자주 변하기 쉽다.
- 다국어 지원이 필요한 경우가 있을 수도 있다.
- 문자열 리터럴은 공간을 많이 차지한다. 보통은 큰 영향이 없지만, 저장 공간을 많이 사용할 수 없는 경우에는 문자열 리터럴 대신 이름 있는 상수나 전역 변수로 소스코드와 별도로 관리하는 것이 낫다.
- 오프 바이 원(Off-by-one) 오류에 주의해라
- 문자열의 부분 문자열은 배열처럼 인덱싱할 수 있다.
- 인덱스 범위를 벗어나 읽거나 쓰는 오류(Off-by-one)를 조심해야 한다.
- 프로그래밍 언어 및 환경이 유니코드(Unicode)의 지원 방식 이해
- 언어마다 유니코드의 지원 방식이 다르다.
- 자바의 경우 기본적으로 모든 문자열이 유니코드를 지원하는 반면, C나 C++의 경우 별도의 라이브러리가 필요하다.
- 기본적으로 유니코드를 지원하지 않는 경우, 조기에 유니코드 문자 셋을 사용할지를 정해야하고, 만약에 사용한다면 언제 어디서 사용할지를 정해야 한다.
- 국제화(internationalization)/지역화(Localization) 전략을 초기에 결정
- 모든 문자열을 외부 리소스에 저장할지, 별도의 빌드를 만들지, 런타임에 언어를 선택하게 할지 결정.
- 단일 알파벳 기반 언어만을 지원하는 경우, ISO 8859 문자 셋 사용을 고려
- 영어와 같은 단일 알파벳 기반 언어만을 지원하면 되는 경우, 유니코드 대신 ISO 8859(확장 아스키)를 사용하는 것도 좋다.
- 복수의 언어를 지원해야 하는 경우 유니코드를 사용
- 문자열 타입 간 일관된 변환 전략이 필요
- 복수의 문자열 타입을 사용하는 경우, 프로그램 내에서는 하나의 형식만을 사용하고 입/출력이 일어나는 시점에만 다른 형식으로 변환하는 하는 방법을 사용할 수 있다.
- 변환 과정에서 발생하는 버그 방지
Strings in C
C++ STL string 클래스에서는 전통적인 C 문자열에서 일어나는 문제점들이 해결되었다. 아래는 C 문자열을 직접 다루는 프로그래머들을 위한 것.
- 문자열 포인터와 문자 배열의 차이 이해
- C에서는 문자열을 문자 배열, 또는 문자열 포인터로 표현할 수 있다.
char* StringPtr = "Some Text String";"Some Text String"은 리터럴 문자열의 포인터고,StringPtr에 그 포인터를 할당하고 있다.StringPtr이 리터럴 문자열을 가리키도록 할 뿐, 문자열을 복사하지 않는다.
- 변수가 문자 배열인지, 문자열 포인터인지를 구분하기 위한 네이밍 컨벤션을 사용
- 문자 배열이 경우 앞에
ach(array of character), 문자열 포인터인 경우 앞에ps를 붙이는 것이 자주 쓰임
- 문자 배열이 경우 앞에
- 문자열의 길이를
CONSTANT + 1로 설정- C-스타일 문자열에서는 맨 마지막에
\0(NULL)이 들어가야 하므로, 이를 위한 자리를 하나 마련해둬야 함. - 간과하는 경우 버퍼 오버 플로가 일어날 수 있다.
CONSTANT를 정하는 것과, 이를 어떻게 해석할지에 대해서도 일관적인 규칙을 사용해야 한다.
- C-스타일 문자열에서는 맨 마지막에
- 문자열을 NULL로 초기화
- C에서는 문자열의 끝을
\0으로 판단한다. 만약 문자열을 null로 초기화하지 않으면 문자열의 끝을 찾지 못할 수도 있고, 관련 연산도 끝나지 않을 수 있다. char EventName[MAX_NAME_LENGTH + 1] = { 0 };과 같이 초기화- 동적으로 문자열을 할당해야하는 경우,
malloc()대신calloc()을 쓰는 것이 좋다.calloc()은 메모리를 0으로 초기화하고 할당하고,malloc()은 초기화 없이 할당.
- C에서는 문자열의 끝을
- 포인터 대신 문자 배열을 사용
- 메모리에 제한이 크게 없는 경우, 웬만하면 문자열 변수는 문자 배열로 선언하는 것이 좋다.
- 포인터 관련 문제가 줄고, 컴파일러도 버그를 쉽게 찾아낸다.
strcpy()대신strncpy()를 사용- C에서 제공되는 문자열 관련 루틴에는 안전한 버전과 위험한 버전들이 있다.
strcmp(),strcpy()와 같은 위험한 루틴들은 NULL 문자를 만날 때까지 실행된다.strncmp(),strncpy()와 같은 안전한 버전의 경우, 최대 길이를 파라미터로 받아 사용한다.
12.5 Boolean Variables
- 프로그램 문서화를 위한 불리언 변수 사용
//Java Example of Boolean Test (Unclear purpose) if ((elementIndex < 0) || (MAX_ELEMENTS < elementIndex) || (elementIndex == lastElementIndex)) { ... }
위 코드는 if 테스트의 목적이 불분명하다. 아래와 같이 하면 if 테스트의 목적이 보다 잘 드러나게 만들 수 있다.
//Java Example of Boolean Test (Clear purpose)
Boolean finished = (elementIndex < 0) || (MAX_ELEMENTS < elementIndex);
Boolean repeatedEntry = (elementIndex == lastElementIndex);
if ( finished || repeatedEntry) {
...
}
- 복잡한 테스트의 단순화를 위한 불리언 변수 사용
- 복잡한 테스트의 경우 여러 번의 수정이 필요할 수 있고, 나중에 테스트를 수정하려 하는 경우 처음의 테스트가 어땠는지 이해하기도 어려워질 수 있다.
- 위 테스트 예제와 같이, 복잡한 하나의 테스트를 여러 개의 간단한 테스트들로 분할하면 읽기 쉬워지고, 오류도 줄어들고, 수정하기도 쉬워진다.
- 필요한 경우, 자신만의 불리언 타입을 만들기
- C++, Java 등에는 불리언 타입이 있지만, C와 같이 불리언 타입이 없는 언어도 있다(헉! 처음 알았음).
- 이러한 경우 자신만의 불리언 타입을 만들어 사용할 수 있다.
int를 논리 표현을 위해 쓰는 것보다, 불리언 타입을 새로 정의해 사용하는 것이 프로그램의 의도를 좀 더 잘 보여주므로 좋다.
//typedef를 이용한 BOOLEAN 타입 정의
typedef int BOOLEAN;
//enum을 이용한 BOOLEAN 타입 정의.
enum Boolean{
True=1,
False=(!True)
};
12.6 Enumerated Types
열거형(enumerated type, enum)은 여러 관련 상수에 이름을 붙여 정의하는 자료형이다. 숫자 대신 의미 있는 영문 이름을 사용할 수 있게 된다.
- 가독성을 위해 열거형을 사용
- 숫자 리터럴을 열거형으로 대체하면 좀 더 읽고 이해하기 쉬워진다.
- 특히 루틴 파라미터를 정의할 때 유용하다. ```cpp //C++ Examples of a Routine Call int result = RetrievePayrollData( data, true, false, false, true );
// 아래와 같이 enum을 이용해 개선할 수 있음=====>
int result = RetrievePayrollData( data, EmploymentStatus_CurrentEmployee, PayrollType_Salaried, SavingsPlan_NoDeduction, MedicalCoverage_IncludeDependents );
+ **신뢰성을 위해 열거형을 사용**
+ named constant를 사용하는 경우, 어떤 값을 적절히 사용하고 있는지 판단하기 어려울 수 있다. 열거형을 사용하면 이와 같은 일을 방지할 수 있다.
```cpp
const int RED = 1;
const int BLUE = 2;
const int KOREA = 1;
const int CHINA = 2;
//...
int func() {
int color = KOREA;
int country = BLUE;
//...
}
- 열거형을 사용하면 수정이 용이해진다
- 불리언 변수의 대체제로 열거형을 사용
- 불리언 변수는 두 가지 상태 밖에 없지만, 열거형을 사용하면 보다 풍부한 상태 정의가 가능해진다
- 유효하지 않은 값 확인
if,else문에서 열거형을 테스트하는 경우, 유효하지 않은 값이 아닌지 확인해야 한다.
- 루프 제한을 위한 열거형의 첫/마지막 엔트리 정의
- 열거형 타입의 첫/마지막 엔트리를
ENUM_FIRST = 0,ENUM_LAST = n - 1와 같이 정의해두면 루프 수행시 이용할 수 있다.
- 열거형 타입의 첫/마지막 엔트리를
- 열거형의 첫 번째 엔트리는 유효하지 않은 값을 위해 남겨두기
- 대부분의 컴파일러는 열거형의 첫 번째 요소에 값 0을 할당한다.
- 이를 제대로 초기화 되지 않은 열거형 변수가 있는지 확인하는 데 사용할 수 있다.
- 프로젝트 내에서 첫/마지막 요소가 어떻게 사용될 것인지 정하고, 일관성 있게 사용하기
InvalidFirst,First,Last를 사용하면 루프를 좀 더 읽기 쉽게 만들 수 있다. 하지만 이 경우 유효 엔트리가 0에서 시작하는지, 1에서 시작하는지 등을 명확하게 정하고, 그것을 일관성 있게 따라야 한다.
- 열거형 원소에 명시적으로 값을 할당하는 경우에 주의
- 아래와 같이 열거형을 정의하고 루프를 하는 경우, 유효하지 않은 1, 3, 5, 7에 해당하는 값도 루프하게 되므로 주의해야 한다.
enum Color {
Color_InvalidFirst = 0,
Color_First = 1,
Color_Red = 1,
Color_Green = 2,
Color_Blue = 4,
Color_Black = 8,
Color_Last = 8
};
If Your Language Doesn’t Have Enumerated Types
열거형을 지원하지 않는 언어의 경우, 전역 변수/클래스를 이용해 비슷하게 만들 수 있다. 특히 클래스를 이용한다면 잘못된 타입을 할당하는 문제를 바로 찾을 수 있게 된다.
12.7 Named Constants
이름 있는 상수(Named Constant)의 경우, 한 번 값을 할당하고 나면 더 이상 그 값을 바꿀 수 없다는 점만 제외하면 변수와 동일하다. 이는 프로그램을 “파라미터화”하는 데 유용하다(코드 전체를 돌면서 하나하나 고치지 않고, 딱 한 곳에서만 바꾸면 되도록).
- 데이터 선언에서 사용하기
- 이름 있는 상수를 사용하면 프로그램의 가독성 및 유지보수성을 높일 수 있다.
- 리터럴 사용을 자제하기(안전한 경우에도!)
- 리터럴을 사용하면, 그 의미를 파악하기 어렵다. 이름 있는 상수를 이용하면 의미를 명확히 하고, 유연성도 높일 수 있다.
- 적절한 스코프의 변수/클래스를 이용해 이름 있는 상수처럼 이용
- 이름 있는 상수를 지원하지 않는 언어의 경우, 적절한 스코프의 변수/클래스를 이용해 비슷하게 사용할 수 있다.
- 일관성 있게 사용하기
- 어디에선 이름 있는 상수를 사용하고 다른 곳에서는 리터럴을 사용하는 경우, 오류에 취약해지기도 하고, 그 오류가 어디서 발생하는지 찾기도 어려워진다.
12.8 Arrays
배열(Array)은 동일한 타입의 아이템들을 묶어, 배열 인덱스를 통해 직접 접근할 수 있도록 만들어 놓은 것이다.
- 모든 배열 인덱스가 배열의 범위 내에 있도록 해야 한다
- 배열의 범위를 벗어난 인덱스를 이용해 접근하는 경우 일어나는 문제가 가장 흔하다.
- **배열 대신 컨테이너를 사용하는 것도 염두에 두기
- 배열의 랜덤 액세스가 코드를 예측하기 어렵고, 오류에 취약하게 만든다는 주장이 있다.
- 배열을 순차 접근이 가능한 다른 컨테이너로 대체하는 것을 고려하자. 이를 이용하면 더 적은 변수 및 변수 참조를 이용하고, 보다 효율적이고 신뢰성 있는 소프트웨어 설계가 가능해진다.
- 배열의 끝점을 확인하기
- 배열의 첫/마지막 요소에 접근할 때 실수가 생길 가능성이 제일 크다. 꼭 확인하자.
- 다차원 배열인 경우, 인덱스의 순서를 체크하기
- 인덱스 교차 접근(index cross-talk)에 주의
- 중첩된 루프문을 사용하는 경우,
Array[i]를Array[j]와 같이 쓰는 실수가 자주 일어나니 주의하자. i나j대신 의미 있는 이름을 사용하는 것도 좋다.
- 중첩된 루프문을 사용하는 경우,
- C의 경우,
ARRAY_LENGTH()매크로를 사용하는 것도 좋다- 아래와 같이 매크로를 정의해놓으면 유용하게 쓸 수 있다.
- 특히 1차원 배열에서 사용하기 좋고, 배열의 크기 변경에 유용하게 대응할 수 있다.
#define ARRAY_LENGTH(X) (sizeof(x)/sizeof(x[0]))
12.9 Creating Your Own Types
프로그래머가 정의한 자료형은 프로그램의 가독성을 높이고, 예기치 못한 변경으로부터 프로그램을 보호하는 데 도움이 된다.
아래와 같은 클래스가 있다고 해보자.
class foo {
float x;
float y;
float z;
};
만약 나중에 float이 아니라 double을 써야한다면 필드를 하나하나 double로 바꿔줘야 한다.
typedef float Field;
class foo {
Field x;
Field y;
Field z;
};
위와 같이 typedef로 자료형을 새로 정의하면, 필드를 하나하나 바꿀 필요 없이 맨 위의 float을 double로 바꾸기만 하면 된다.
- 수정이 용이해짐
- 새로운 타입을 만드는 일은 쉽고, 프로그램의 유연성을 더해준다.
- 과도한 정보 분산 방지
- 하드 코딩은 자료형과 관련한 세부 사항들을 프로그램 전반에 흩뜨려놓는다.
- 신뢰성 증가
- 언어의 약점 극복
- 사용하는 언어가 원하는 자료형을 제공하지 않는 경우(ex.C의 불리언)를 해결하는 데 도움이 된다.
사용자 정의 자료형을 만들기 위한 가이드라인
- 실제 문제에 기반한 이름 짓기
- 컴퓨터 데이터 형식을 나타내는 이름(ex.
BigInteger,LongString) 보다는 실제 세계의 문제와 관련된 정보를 반영할 수 있는 이름을 짓는 것이 좋다.
- 컴퓨터 데이터 형식을 나타내는 이름(ex.
- 표준 자료형 사용을 피하기
- 자료형이 변할 가능성이 있다면, 표준 자료형을 사용하기 보다는 사용자 정의 타입을 사용하는 것이 좋다.
- 수정 가능성이 높아지고, 가독성도 높아진다.
- 표준 자료형은 재정의하지 않기
- 이식성을 고려한 대체 타입 정의
- 하드웨어 플랫폼에 따라 다른 타입이 필요해지는 경우, 사용자 정의 자료형을 만드는 것이 좋다.
- 예)
int대신 사용자 정의 타입INT32를 사용하기
typedef대신 클래스를 만드는 것도 고려하기- 더 복잡한 기능이나 추가적인 제어가 필요한 경우, 클래스를 사용하는 것이 나은 경우도 있다.


