13장 - 특이한 데이터형
Edited by / (frog-slayer)

13.1. Structures
구조체(structure)는 서로 같거나 다른 데이터들로 구성된 자료형이다. C, C++의 경우 struct, VB의 경우 Structure에 해당하는 것으로, 자바나 C++의 경우 클래스를 구조체처럼 사용하는 경우도 있다.
보통은 접근제한자나 여러 기능들을 사용하기 위해 클래스를 이용하지만, 어떨 때는 직접 데이터 블럭을 조작하는 것이 유용할 때가 있다.
- 데이터 간 관계를 명확히 하기 위해 사용
- 때로는 연관된 아이템들을 묶을 필요가 있다.
- 구조체를 이용하면 그 아이템들을 한 데 묶으면서, 그 관계를 명확히 할 수도 있다.
- 데이터 블럭의 연산을 간단히 하기 위해 사용
- 구조체 요소 하나하나에 연산하지 않고, 한 번에 묶어서 처리할 수 있다.
- 루틴의 파라미터 목록을 간단히 하기 위해 사용
- 루틴 파라미터에 구조체 요소들을 각각 넣지 않고, 구조체를 하나만 넣게 하면 좀 더 깔끔하고 읽기 쉬운 코드를 만들 수 있다.
- 단 구조체의 요소 몇 가지만 필요한 경우, 구조체를 통째로 넘기는 것은 좋지 않다. 필요한 필드만 전달하고, 불필요한 데이터들까지 넘기지는 않는 게 좋다.
- 유지보수를 용이하게 하기 위해 사용
- 구조체의 어떤 필드를 삭제/수정하는 경우, 그 필드를 사용하는 부분들만 수정하면 된다.
각 컴포넌트가 그 자체로는 의미가 없고, 어떤 컬렉션의 부분일 때만 의미를 가진다면 구조체를 사용하는 것이 좋다.
13.2. Pointers
포인터 사용은 오류 발생의 주된 요인이라, 자바, C#, VB 등에서는 더 이상 직접적인 포인터 조작을 지원하지 않는다. 다만 사용하는 언어가 포인터 사용을 지원하지 않는다고 하더라도, 포인터를 잘 이해하면 그 언어가 어떻게 동작하는지 이해하는 데에도 도움을 줄 것이다.
Paradigms for Understanding Pointers
개념적으로, 모든 포인터는 두 부분을 가지고 있다.
- 메모리 내 위치
- 포인터가 가리키는 데이터를 사용하려면 그 데이터의 주소로 가야 한다.
- 내용을 어떻게 해석할 것인지에 대한 정보
- 그 주소로 갔다면, 해당 위치의 메모리에 담긴 내용을 해석해야 한다.
- 서로 다른 타입의 포인터가 같은 위치를 가리킬 수는 있지만, 그 중 해당 위치에 담긴 내용을 제대로 해석할 수 있는 것은 하나 뿐이다.
General Tips on Pointers
포인터 오류는 보통, 포인터가 가리키지 않아야 할 곳을 가리킬 때 일어난다. 잘못된 포인터 변수에 값을 할당하면, 쓰지 않아야 할 메모리 영역에 데이터를 쓰게 된다(memory corruption).
- 메모리 손상의 증상
- 시스템 충돌
- 계산 결과 변경
- 예측 불가능한 프로그램 플로
- 아무 것도 안 일어남 <- 이게 제일 무섭다
포인터 오류는 증상이 실제 원인과 관련이 없는 경우가 있기 때문에 찾아내기 매우 어렵다. 따라서 다음의 두 주요 전략이 필요하다.
- 포인터 오류가 발생하지 않도록 예방
- 찾기 어려우므로, 처음부터 오류가 발생하지 않게 예방하는 게 중요하다.
- 포인터 오류를 조기에 탐지
- 증상이 예측 불가능하므로, 가능한 한 빠르게 오류를 발견하고 수정할 수 있어야 한다.
아래는 이를 달성하기 위한 가이드라인들.
- 포인터 관련 작업을 루틴/클래스에서 분리해서 처리
- 예를 들어 프로그램 내에서 하나의 연결 리스트를 여러 곳에서 사용해야 하는 경우, 사용되는 각각의 장소에서 리스트를 순회하기 보다, 여러 접근 루틴을 만들어서 사용하는 것이 좋다.
- 포인터를 직접 사용하게 되는 곳을 줄여 실수 발생 지점을 줄이기
- 포인터 작업의 캡슐화를 통해 해당 코드의 재사용성도 향상됨
- 포인터는 선언과 동시에 할당하기
- 값이 할당되기 전에 사용해서 발생하는 오류를 방지
- 할당된 곳과 같은 스코프 수준에서 삭제
- 같은 루틴, 혹은 관련된 루틴에서 메모리 해제.
- 생성자에서 할당했다면, 소멸자에서 포인터를 해제.
- 포인터는 사용하기 전에 확인하기
- 예상되는 메모리 범위가 있다면, 포인터를 사용하기 전에 해당 범위를 벗어나지는 않는지 확인할 것.
- 그 범위는 접근 루틴을 통해 자동으로 처리할 수 있음
- 포인터로 참조한 변수를 사용하기 전에 확인
- 포인터가 가리키는 변수의 값을 사용하기 전에 확인할 것.
- 접근 루틴을 통해 자동으로 처리할 수 있음.
- 도그-태그(Dog-tag) 필드를 사용한 메모리 손상 확인
- 도그 태그, 혹은 태그 필드: 에러 확인을 목적으로 쓰이는 필드. 해당 값이 변했다면 메모리가 손상된 것으로 판단한다.
- 구조체 정의 시 태그 필드를 추가
- 할당 시 태그 값을 설정
- 메모리 사용 시 태그 필드 확인. 변경되었으면 데이터 손상
- 메모리 해제 시 태그 필드의 값을 변경해 재해제 오류를 감지
- 메모리 블럭의 앞쪽에 도그 태그) 잘못된 재해제를 감지할 수 있음
- 메모리 블럭의 뒤쪽에 도그 태그) 범위를 벗어난 메모리에 덮어 쓰는 것을 확인할 수 있음
- 도그 태그, 혹은 태그 필드: 에러 확인을 목적으로 쓰이는 필드. 해당 값이 변했다면 메모리가 손상된 것으로 판단한다.
- 명시적 중복성 추가
- 태그 필드를 사용하는 대신, 특정 필드를 두 번 사용하는 방법도 가능.
- 특정 필드의 값을 저장하고, 나중에 확인했을 때 저장했던 값과 달라진다면 메모리가 손상됐음을 알 수 있다.
- 오버헤드가 클 수는 있지만, 포인터 작업을 중앙 집중화한 경우 편하게 쓸 수는 있다.
- 명확성을 위한 추가 포인터 변수 사용
- 하나의 포인터 변수로 여러 역할을 하는 일은 피해야 한다.
- 하나의 변수는 명확한 하나의 목적만을 위해 사용해야 한다.
- 복잡한 포인터 표현의 단순화
- 복잡한 포인터 식은 읽기 어렵다. 불필요하고 복잡한 포인터 표현을 줄이고, 이해하기 쉬운 이름의 변수에 값을 저장해 코드의 가독성을 높이고 성능상의 이점도 높이자.
- 그림 그리기: 포인터 사용이 너무 혼란스러우면, 그림을 그려보는 것도 도움이 된다.
- 연결 리스트의 포인터는 정확한 순서로 삭제할 것
- 동적 할당 연결 리스트에서 가장 많이 일어나는 실수 중 하나는 리스트의 첫 번째 포인터를 삭제해 다음 포인터로 가지 못하는 것.
- 메모리의 비상 예비 공간 할당
- 동적 메모리를 사용하면 갑자기 메모리가 부족해져 잘못 프로그램을 종료하게 될 수도 있다.
- 작업을 저장하고, 정리하고, 제대로 종료하기 위한 위한 예비 공간을 마련해두는 것도 좋다.
- 해제 시 쓰레기 값으로 채우기
- 포인터는 언제 해제되는지 알기 어렵고, 시간이 지나도 유효한 값으로 보일 때가 있다.
- 해제가 될 때 내부를 쓰레기 값으로 채워준다면, 메모리 해제 후 오류를 더 잘 감지할 수 있게 된다.
- 마찬가지로 접근 루틴을 사용하면 자동으로 처리할 수 있다.
//C Example of Forcing a Deallocated Object to Contain Junk Data
pointer->SetContentsToGarbage();
delete pointer;
- 포인터를 삭제/해제한 후에는 null로 설정
- 삭제/해제 시 포인터를 null로 설정하면, 잘못 읽는 일은 몰라도, 잘못 쓰는 일은 막을 수 있다.
//C++ Example of Setting a Pointer to Null After Deleting It
pointer->SetContentsToGarbage();
delete pointer;
pointer = NULL;
- 변수 삭제 전 잘못된 포인터는 아닌지 확인
- 이미 삭제/해제된 포인터를 삭제/해제하는 일은 심각한 오류로 이어질 수도 있지만, 이를 잘 대처하는 언어는 그리 많지 않다.
- 해제된 포인터를 null로 설정하는 방식으로, 포인터를 다시 해제하려하기 전에 이미 해제된 것은 아닌지 확인할 수 있다.
//C++ Example of Asserting That a Pointer Is Not Null Before Deleting It
ASSERT( pointer != NULL, "Attempting to delete null pointer." );
pointer->SetContentsToGarbage();
delete pointer;
pointer = NULL;
- 포인터 할당 추적
- 할당한 포인터들의 리스트를 만들고, 이 리스트를 통해 해당 포인터가 사용 중인지 그렇지 않은지를 확인하는 방법이다.
//C++ Example of Checking Whether a Pointer Has Been Allocated
ASSERT( pointer != NULL, "Attempting to delete null pointer." );
if ( IsPointerInList( pointer ) ) {
pointer->SetContentsToGarbage();
RemovePointerFromList( pointer );
delete pointer;
pointer = NULL;
}
else {
ASSERT( FALSE, "Attempting to delete unallocated pointer." );
}
- 중앙 집중화 전략을 위한 커버 루틴 작성
- 여기서 소개된 여러 테크닉들은 서로 중복이거나 상호배제적일 수 있다.
- 중앙 집중화를 통해 에러와 오버헤드를 줄일 수 있다.
- 예를 들어 C++의 경우,
SAFE_NEW,SAFE_DELETE와 같은 루틴을 만들어 메모리 할당/해제를 안전하게 마칠 수도 있다. - 개발 버전/운영 버전에 따라 다르게 동작하게 만들 수도 있다.
//C++ Example of Putting a Wrapper Around Pointer Deletion Code
#define SAFE_DELETE( pointer ) { \
ASSERT( pointer != NULL, "Attempting to delete null pointer."); \
if ( IsPointerInList( pointer ) ) { \
pointer->SetContentsToGarbage();
RemovePointerFromList( pointer ); \
delete pointer; \
pointer = NULL; \
} \
else { \
ASSERT( FALSE, "Attempting to delete unallocated pointer." ); \
} \
}
- 포인터를 사용하지 않는 기술 사용
- 포인터는 생각보다 이해하기 어렵고, 에러에도 취약하고, 사용 기기에 의존적이고, 이식성도 낮다. 대안이 있으면 굳이 포인터를 사용하지 않고 다른 것을 쓰는 게 신상에 좋을 수도 있다.
C++ Pointer Pointers
- 포인터와 참조의 차이를 이해하기
- C++에서는 포인터(*)와 참조(&) 모두 객체 참조에 사용할 수 있다.
- 단 참조는 꼭 객체를 참조해야 하고, NULL을 가질 수 없다.
- 포인터는 NULL을 가질 수 있고, 초기화 후에도 참조 대상을 변경할 수 있다.
- 포인터는 “참조로 전달”, const 참조는 “값으로 전달”에 사용
- auto_ptr 사용하기(deprecated)
- 스코프를 벗어나면 자동으로 메모리를 삭제해주기 때문에 메모리 누수를 많이 줄일 수 있다.
- 스마트 포인터 잘 이용하기
unique_ptr,shared_ptr과 같은 스마트 포인터를 사용하면 알아서 메모리를 관리해준다.
C-Pointer Pointers
- 포인터 타입을 명시적으로 지정하기
- 어떠한 변수에든
char,void포인터를 사용할 수 있다. - 명시적으로 타입을 지정하면 컴파일러가 오류를 찾아줄 것이므로 꼭 그렇게 하자.
- 어떠한 변수에든
- 타입 캐스팅 자제
- 컴파일러의 타입 미스매칭 탐지 능력을 무력화해 오류가 발생하기 쉽다.
- 꼭 필요한 경우가 아니라면 줄이도록 하자.
- 파라미터 전달시 애스터리스크(*) 규칙을 따를 것
- 호출하는 루틴에 값을 되돌려주려면 애스터리스크를 붙이기
sizeof()를 이용해 메모리 할당 크기 구하기- 크기를 직접 찾기 보다는
sizeof()를 쓰는 게 좋다. - 컴파일 시간에 계산되므로 성능 이슈가 일어나지 않고, 이식성도 좋다.
- 크기를 직접 찾기 보다는
13.3. Global Data
전역 변수는 프로그램 어디에서나 접근할 수 있는 데이터다. 지역 변수를 쓰는 것보다 위험하기는 하지만, 여러 곳에서 사용할 수 있다는 장점도 있다.
Common Problems with Global Data
- 원하지 않게 수정될 수 있음
- “Aliasing” 문제 발생
- 전역 변수가 동시에 파라미터 이름으로 쓰이는 경우, 같은 변수가 여러 이름으로 쓰이는 문제가 발생할 수 있음
- 재진입성 문제
- 멀티스레드 코드에서, 서로 다른 스레드가 전역 변수에 접근/수정하는 경우에 문제가 발생할 수 있음
- 코드 재사용성 저하
- 전역 변수를 사용하는 부분 모듈은, 그 부분만 똑 떼서 다른 곳에서 사용하기 힘들다.
- 초기화 순서 문제
- C++의 경우, 여러 소스 파일을 컴파일/링크 할 때 전역 변수의 초기화 순서가 정의되어 있지 않음
- 때문에 한 파일의 전역 변수가 다른 파일의 전역 변수에 의존하는 경우, 예상치 못한 초기화 문제가 발생할 수 있다.
- 모듈성 문제
- 전역 변수에 모든 부분이 묶여 있으면, 한 부분을 수정했을 때 다른 부분들에도 연달아 영향을 미칠 가능성이 있다.
Reasons to Use Global Data
전역 변수를 사용하는 게 유용한 경우들이 있다.
- 전역 값 보존
- 프로그램 전체에서 개념적으로 중요한 데이터를 저장해야 하는 경우
- ex) 프로그램의 상태(대화형 vs 커맨드 라인, 정상 vs 오류 복구 모드)
- 또는 프로그램 내 모든 루틴들이 사용하는 데이터 테이블 등
- 이름 상수 대용으로 사용
- C++, 자바, VB 등은 이름 상수를 지원하지만, 파이썬, 펄 등은 지원하지 않음.
- 전역 변수를 사용해 상수를 대신할 수 있음
- 열거형 타입 대용
- 매우 자주 쓰이는 데이터 처리
- 모든 루틴의 파라미터 리스트에 등장하는 변수가 있다면, 전역 변수를 사용해도 좋다.
- 단 그런 경우는 적고, 해당 데이터를 사용하는 하나의 클래스로 패키징되는 루틴들일 경우가 많다.
- 트램프 데이터(tramp data) 제거
- 단순히 다른 루틴이나 클래스로 전달하기 위해 어떤 루틴이나 클래스에 데이터를 전달해야하는 경우가 있다.
- 호출 체인 중간에 있는 루틴이 해당 객체를 사용하지 않는 경우, 이 데이터를 트램프 데이터라 부르며, 전역 변수를 이용해 트램프 데이터를 제거할 수 있다.
Use Global Data Only as Last Resort
전역 데이터를 사용하기 전에 생각해볼 몇 가지 대안들.
- 일단은 지역 변수로 만들고, 정말 필요할 때만 전역 변수로 만들기
- 처음에는 모든 변수들을 각 루틴의 로컬 변수로 만든다.
- 만약 다른 곳에서도 해당 변수가 필요하다면, private이나 protected 변수로 만든다.
- 그래도 꼭 전역으로 만들어야 한다면, 그때는 전역 변수로 만들어도 좋다.
- 처음부터 전역 변수로 만들면 다시 지역 변수로 만들기 어렵지만, 지역 변수로 시작하면 전역 변수가 필요하지 않을 수도 있다.
- 전역 변수와 클래스 변수를 구분
- 전역 변수: 정말로 프로그램 전체에서 접근되는 변수
- 클래스 변수: 특정 루틴 셋 안에서만 자주 쓰이는 변수.
- 클래스 변수의 경우, 클래스 내부에서는 자유롭게 사용해도 좋지만, 외부에서 접근해야 하는 경우에는 직접 접근하기 보다는 루틴을 통해 접근하는 것이 좋다.
- 접근 루틴 사용
Using Access Routines Instead of Global Data
전역 데이터를 직접 다루는 것보다 접근 루틴을 사용하면 훨씬 좋다.
- 접근 루틴의 장점
- 데이터에 대한 중앙 집중형 제어가 가능해진다.
- 나중에 구조 구현을 바꿔야하는 경우, 해당 데이터를 참조하는 모든 곳의 코드를 바꾸지 않고 한 곳만 바꾸면 된다.
- 변수에 대한 모든 참조에 대한 바리케이드 제공
- 직접 수정하는 경우 간과할 수 있는 잘못된 접근들을 방지할 수 있다.
- 자동으로 정보 은닉 가능
- 프로그램의 다른 부분을 바꾸지 않고, 접근 루틴의 내부만 수정하면 된다.
- ADT로의 변환이 용이
- 전역 데이터를 직접 다룰 때와는 달리, 새로운 추상화 단계를 만들 수 있게 한다.
- 가독성 증가
- 데이터에 대한 중앙 집중형 제어가 가능해진다.
- 접근 루틴을 어떻게 쓸 것인가
- 데이터를 클래스에 숨긴다.
static키워드 등을 이용해 해당 데이터의 단일 인스턴스만 사용한다- 데이터 조회 및 수정을 위한 루틴을 작성해, 클래스 밖의 코드에서는 해당 접근 루틴을 이용해 데이터에 접근한다.
- 클래스를 지원하지 않는 언어의 경우에도, 전역 변수는 제한적으로만 사용해야 한다. 아래는 그런 경우를 위한 가이드 라인
- 모든 코드가 접근 루틴을 통해서만 데이터를 수정하도록 강제
- 모든 전역 데이터 앞에
g_접두어를 붙이도록 하고, 해당 변수의 접근 루틴을 제외한 어느 곳에서도 해당 데이터에 직접 접근하는 일이 없도록 하기
- 모든 전역 데이터 앞에
- **전역 데이터를 한 데 모으지 않기
- 그냥 모든 전역 데이터를 한 곳에 두고 접근 루틴을 작성하는 것만으로는 전역 데이터의 문제는 해결할 수 있을지 몰라도, 정보 은닉, ADT 등의 이점을 누릴 수는 없다.
- 클래스를 사용했다면 각 전역 변수가 어떤 클래스에 속하게 될 것인지를 생각해보고, 관련 변수와 그 접근 루틴들끼리 그룹화해서 나누자.
- 전역 변수 접근 제어를 위한 락(lock) 사용
- 전역 변수 값을 사용하거나 수정하기 전에 체크 아웃하고, 사용 후에는 다시 체크인하기.
- 사용 중에 프로그램의 다른 부분이 해당 전역 변수를 체크 아웃하려고 하면 에러 메시지를 표시하거나 어설션 일으키기
- 단, 개발 단계에서는 몰라도 프로덕션 단계에서는 보다 정교한 방식이 필요
- 접근 루틴의 추상화 수준 설계
- 접근 루틴은 구체적인 구현 수준이 아니라, 문제 도메인의 수준에서 설계 해야 한다.
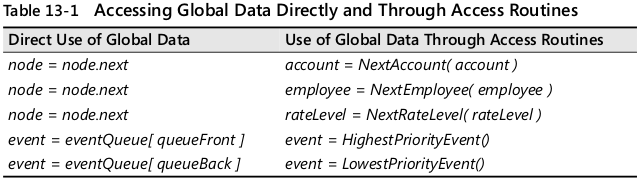
- 구조를 직접 사용하면 내부 동작 방식과 해당 데이터가 표현하는 실제 개념이 한 코드에서 동시에 나타나지만, 추상화된 접근 루틴을 사용하면 구조의 내부 구현을 감춰 해당 코드가 무엇을 하는지에 집중할 수 있게 된다.
- 모든 데이터 접근을 같은 추상화 수준으로 유지
- 데이터 접근 방식에는 일관성이 있어야 한다. 접근 루틴과 직접 조작을 혼용하는 경우는 좋지 않다.
- 모든 코드가 접근 루틴을 통해서만 데이터를 수정하도록 강제
How to Reduce the Risks of Using Global Data
전역 데이터는 대부분 제대로 설계/구현되지 않은 클래스 데이터인 경우가 많다. 실제로 “전역” 데이터인 경우도 있지만, 이 경우에도 접근 루틴을 이용해 잠재적인 문제들을 최소화하는 것이 좋다.
- 전역 변수임을 확실히 드러낼 수 있는 네이밍 컨벤션 사용
- 글로벌 변수 목록 작성
- 중간 계산 결과를 전역 변수에 적용하지 말 것
- 전역 변수의 값 수정이 필요한 경우, 최종 결과만을 저장할 것.
- 모든 전역 데이터를 담은 거대 객체를 만들어 모든 곳에 전달하는 방식은 피할 것
- 불피요한 오버헤드 발생.

