22장 - 개발자 테스트
Edited by / (frog-slayer)

테스트는 가장 널리 알려진 퀄리티 향상 활동이다. 소프트웨어를 테스트하는 방법에는 여러가지가 있는데, 어떤 것은 개발자들이 수행하고 어떤 것은 테스트 전문 인력이 수행한다.
- 단위 테스트(Unit testing)
- 한 프로그래머(팀)이 만든 클래스, 루틴, 혹은 작은 프로그램이 보다 큰 시스템과 독립적으로 실행될 수 있는지를 테스트.
- 컴포넌트 테스트(Component testing)
- 여러 프로그래머(팀)이 만든 클래스, 패키지, 작은 프로그램, 혹은 프로그램 요소가 보다 큰 시스템과 독립적으로 실행될 수 있는지를 테스트.
- 통합 테스트(Integration testing)
- 여러 프로그래머(팀)이 만든 둘 이상의 클래스, 패키지, 컴포넌트, 서브시스템의 조합이 잘 실행되는지를 테스트. 두 클래스가 만들어진 직후 시작해, 전체 시스템이 완성되기 전까지 지속적으로 수행.
- 회귀 테스트(Regression testing)
- 소프트웨어 결함을 찾기 위해 이전에 실행했던 테스트 케이스를 반복적으로 수행.
- 시스템 테스트(System testing)
- 다른 소프트웨어/하드웨어 시스템과의 통합을 포함해, 전체 설정 내에서의 소프트웨어 작동 테스트. 보안, 성능, 자원 소모, 타이밍 문제 등의 이슈를 테스트.
이 챕터에서의 테스트는 보통 개발자들이 수행하는 테스트들이다. 이외에도 베타 테스트, 고객-인수 테스트, 성능 테스트, 플랫폼 테스트, 스트레스 테스트, 사용성 테스트, 설정 테스트 등 전문 인력(및 소수의 개발자)이 수행하는 테스트들도 있다.
테스트는 보통 블랙 박스 테스트와 화이트 박스 테스트의 두 카테고리로 나뉜다.
- 블랙 박스 테스트(Black-box testing)
- 테스터가 테스트되는 항목 내부를 볼 수 없는 테스트
- 화이트 박스 테스트(White-box testing, glass-box testing)
- 테스터가 테스트되는 항목의 내부 동작을 확인할 수 있는 테스트
- 개발자가 자신이 작성한 코드를 테스트하는 경우가 대표적인 예
테스트와 디버깅을 같은 의미로 사용하는 프로그래머들도 있지만, 사려 깊은 프로그래머들은 둘을 잘 구분한다.
- 테스트: 에러를 탐지.
- 디버깅: 이미 탐지된 에러의 근본 원인을 진단하고 고치는 일
22.1 Role of Developer Testing in Software Quality
테스트는 중요한 소프트웨어 품질 관리 활동이지만, 단독으로는 충분하지 않다.
- 테스트의 목적은 다른 개발 활동의 목적과 상충된다.
- 테스트의 목적은 에러를 찾는 것이고, 성공적인 테스트는 소프트웨어를 붕괴시킬 수도 있다.
- 다른 개발 활동의 목적은 에러를 방지하고 소프트웨어가 붕괴되지 않도록 하는 것이다.
- 테스트를 통과했다고 해서 에러가 없다는 것을 증명하지는 못한다.
- 완벽한 소프트웨어라 에러를 발견하지 못했을 수도 있지만, 이는 비효율적이고 불완전한 TC 때문일 수도 있다.
- 테스트만으로 소프트웨어의 품질을 높일 수는 없다.
- 테스트 결과는 분명 품질에 대한 지표이지만, 그 자체로 높은 품질을 증명하는 것은 아니다.
- 소프트웨어를 개선시키려면 테스트만 자주할 것이 아니라 개발을 잘 해야 한다.
- 테스트를 할 때에는 오류를 발견할 것이라는 가정이 중요하다.
- 오류가 없을 것이라 가정하면 실제로 오류가 있어도 지나치기 쉽다.
질문 1) 개발자 테스트에는 얼마나 많은 시간을 쏟아야 할까? 흔히 전체 프로젝트의 50%에 해당하는 시간을 쏟아야 한다는 말도 있지만, 사실 이 50%는
- 디버깅을 포함한 시간이다. 테스트 자체는 훨씬 적은 시간을 쓴다.
- “써야 하는” 시간이 아니라, “쓰인” 시간을 나타낸다.
- 개발자 테스트 이외의 독립적인 테스트를 포함한 시간이다.
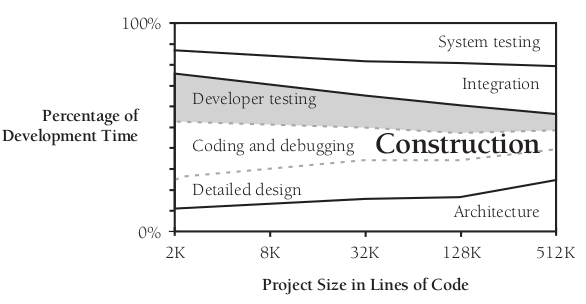 개발자 테스트는 프로젝트의 규모와 복잡도에 따라 전체 프로젝트 시간의 8~25%를 차지해야 한다.
개발자 테스트는 프로젝트의 규모와 복잡도에 따라 전체 프로젝트 시간의 8~25%를 차지해야 한다.
질문 2) 개발자 테스트의 결과를 가지고 무엇을 해야할까?
- 가장 먼저 개발 중인 제품의 신뢰성을 평가하는 데 쓰인다.
- 소프트웨어 수정에 대한 가이드를 제공한다.
- 시간에 따른 결함의 기록은 가장 흔히 일어나는 에러의 종류를 밝히는 데에 도움을 준다. 이 정보는 교육에 쓰거나, 미래에 테스트 케이스를 설계하는 데 쓸 수 있다.
Testing During Construction
- 화이트 박스 테스트
- 화이트 박스 테스트의 중요성을 간과하는 경우가 많다. 예컨대 클래스를 만들 때, “어떻게” 클래스가 실제로 동작하는지보다 클래스가 “무엇을” 하는지에 더 큰 관심을 갖고 테스트하는 경우가 그렇다.
- 하지만 클래스의 입/출력 뿐만 아니라 그 내부 동작이 어떤지도 본다면, 클래스를 좀 더 정밀하게 테스트할 수 있다. 단 자신이 작성한 코드를 테스트할 때에는 주의가 필요한데, 코드를 작성할 때와 같은 시각으로 테스트를 진행하면 오류를 발견하지 못할 수도 있기 때문이다. 이럴 때에는 블랙 박스 테스트를 하는 것도 도움이 된다.
- 단위 테스트
- 통합/시스템 테스트 전략과 상관없이, 각 단위는 다른 것과 결합하기 전에 반드시 테스트해야 한다.
- 여러 개의 루틴을 한 번에 테스트하지 말고, 이미 테스트가 완료된 루틴 그룹에 새로운 루틴을 하나씩 추가하면서 테스트하는 것이 훨씬 이해하고 디버깅하기 쉽다.
- 협업 개발 방식을 화용하면 테스트만으로는 발견하기 어려운 결함도 찾아낼 수 있다.
- 테스트를 많이 수행했다는 사실이 실제로 테스트가 제대로 됐음을 의미하지는 않는다.
- 기본적인 테스트 개념을 잘 이해하는 것이 더 낫고 효율적인 테스트를 수행하는 데 도움을 준다.
22.2 Recommended Approach to Developer Testing
체계적인 개발자 테스트는 최소한의 능력으로 오류를 찾을 수 있도록 한다.
- 연관된 각 요구 사항을 테스트하라.
- 테스트 될 각 단위를 작성하기 전에, 요구 사항 단계에서, 혹은 최대한 빨리 테스트 케이스를 계획하라.
- 요구 사항에 빠진 것이 있지는 않은지 고려해야 한다. 보안 수준, 저장 장치, 설치 순서, 시스템 신뢰성 등은 요구 사항 단계에서 간과되기 쉽다.
- 설계 상 연관된 것들 각각을 테스트하라.
- 테스트 될 루틴이나 클래스를 코딩하기전, 설계 단계에서, 혹은 최대한 빨리 테스트 케이스를 계획해야 한다.
- 요구 사항/설계 테스트를 하기 위한 세부 테스트 케이스를 추가할 때에는 “기초 테스트”를 사용해야 한다.
- 우선은 데이터 흐름 테스트를 추가하고 나서 남은 테스트 케이스를 추가하기
- 적어도 코드의 모든 줄을 테스트해야 한다.
- 현재 프로젝트나 이전의 프로젝트에서 일어났던 에러들에 대한 체크리스트 만들기
요구사항 단계나 설계 단계의 오류는 단순한 코딩 오류보다 대가가 크다. 제품을 만들 때에는 테스트 케이스도 함께 설계해 그런 오류들을 줄여야 한다. 결함은 최대한 빨리 찾아내야 한다. 빠르게 수정하는 것이 더 값싸다.
Test First or Test Last?
테스트 케이스는 먼저 작성하는 것이 좋다. 결함이 코드에 삽입되는 시점과 결함을 발견하고 제거하는 시점 간의 간극을 최대한 줄일 수 있기 떄문이다.
- 테스트 케이스를 코딩 이전에 작성한다고 해서 더 많은 노력이 드는 것은 아니다.
- 결함을 보다 일찍 찾고 쉽게 수정할 수 있다.
- 코드를 작성하기 전, 요구 사항과 설계에 대해 조금 더 생각할 기회가 생긴다.
- 요구 사항 문제를 조금 더 빠르게 발견할 수 있게 된다.
- 미리 만들어 놓은 테스트 케이스가 있다면, 나중에 테스트를 할 때에도 사용할 수 있다.
Limitations of Developer Testing
- 개발자 테스트는 보통 “클린 테스트”(clean test)다.
- 클린 테스트: 코드가 동작하는지를 테스트
- 더티 테스트: 코드가 제대로 동작하지 않는 모든 경우를 테스트
- 미성숙한 테스트 조직의 클린:더티 비는 5:1, 성숙한 테스트 조직의 비는 1:5인 경향이 있다.
- 낙관적인 테스트 커버리지
- 프로그래머들은 평균적으로 자신이 95%의 테스트 커버리지를 달성했다고 믿는다.
- 하지만 가장 잘 쳐줘도 80%, 최악의 경우에는 30%, 보통은 5-60%의 커버리지를 가진다.
- 보다 정교한 테스트 커버리지를 간과하는 경향이 있다.
- 대부분의 개발자는 “100% 문장 커버리지”(statement coverage)만 달성하면 된다고 생각하는 경우가 많다.
- 하지만 이보다는 “100% 분기 커버리지”(branch coverage)를 달성하는 것이 더 좋다.
위 한계가 개발자 테스트의 가치를 떨어트리는 것은 아니다. 보다 적절한 관점에서 개발자 테스트를 수행하자. 개발자 테스트 단독으로는 충분하지 않고, 독립 테스트, 협업 기반 구현 등과 함께 하는 것이 좋다.
22.3 Bag of Testing Tricks
테스트를 통해 프로그램의 정당성을 증명하기는 어렵다. 이를 “증명”하려면 모든 가능한 입력(조합)을 테스트해야 하기 때문이다.
Incomplete Testing
가능한 모든 경우를 테스트하는 것이 불가능하므로, 실제로는 가장 에러를 찾을 수 있을 법한 테스트 케이스를 골라 테스트해야 한다.
테스트 케이스를 고를 때는 같은 것만을 계속해서 알려주는 테스트 케이스를 찾기보다는, 차이를 잘 보여줄 수 있는 테스트 케이스를 골라야 한다.
Structured Basis Testing
프로그램의 각 문장은 적어도 한 번은 테스트해야 한다. 만약 해당 문장이 논리 구문이라면, 해당 조건식이 얼마나 복잡한가에 따라 테스트를 다양화해 해당 문장을 제대로 테스트 했는지 확인해야 한다. 가장 쉬운 방법은 프로그램을 통과하는 경로 수를 계산하고, 해당 경로들을 모두 실행하는 최소한의 테스트 케이스를 만드는 것이다.
코드 커버리지/논리 커버리지의 경우, 프로그램을 통과하는 모든 경로를 테스트하는 것은 동일하지만, “최소한”의 테스트 케이스를 이용한다는 점은 빠져있다. 따라서 코드 커버리지/논리 커버리지 테스트를 사용하는 경우, 필요 이상의 테스트 케이스를 만들게 될 수도 있다.
다음과 같은 방식으로 필요한 최소의 테스트 케이스 수를 계산할 수 있다.
- 루틴을 곧바로 통과하는 경로 1개로 시작
if, while, repat, for, and, or등의 키워드를 만날 때마다 1씩 추가.case문의 각 케이스마다 1을 추가.default케이스가 없는 경우 1을 더 추가
//Simple Example of Computing the Number of Paths Through a Java Program
Statement1; //count 1
Statement2;
if ( x < 10 ) {//count 2
Statement3;
}
Statement4;
위의 예에서는 모든 경로를 커버하기 위해 최소 2개의 테스트 케이스가 필요하다.
if의 조건을 만족하는 경우if의 조건을 만족하지 않는 경우
더 복잡한 예를 보자.
//Example of Computing the Number of Cases Needed for Basis Testing of a Java Program
//1
// Compute Net Pay
totalWithholdings = 0;
for (id = 0; id < numEmployees; id++) {//2
// compute social security withholding, if below the maximum
if (m_employee[id].governmentRetirementWithheld < MAX_GOVT_RETIREMENT) {//3
governmentRetirement = ComputeGovernmentRetirement(m_employee[id]);
}
// set default to no retirement contribution
companyRetirement = 0;
// determine discretionary employee retirement contribution
if (m_employee[id].WantsRetirement && EligibleForRetirement(m_employee[id])) {//4, 5
companyRetirement = GetRetirement(m_employee[id]);
}
grossPay = ComputeGrossPay(m_employee[id]);
// determine IRA contribution
personalRetirement = 0;
if (EligibleForPersonalRetirement(m_employee[id])) {//6
personalRetirement = PersonalRetirementContribution(m_employee[id], companyRetirement, grossPay);
}
// make weekly paycheck
withholding = ComputeWithholding(m_employee[id]);
netPay = grossPay - withholding - companyRetirement - governmentRetirement - personalRetirement;
PayEmployee(m_employee[id], netPay);
// add this employee's paycheck to total for accounting
totalWithholdings = totalWithholdings + withholding;
totalGovernmentRetirement = totalGovernmentRetirement + governmentRetirement;
totalRetirement = totalRetirement + companyRetirement;
}
SavePayRecords(totalWithholdings, totalGovernmentRetirement, totalRetirement);
여기서는 최소 6개의 TC가 필요하다. 단 임의의 6개의 테스트 케이스가 모든 경우를 커버할 수 있다는 것은 아니다. 각 키워드마다 true가 되는 경우, false가 되는 경우 각각에 대한 TC를 만들도록 하자. 아래는 모두를 커버할 수 있는 테스트 케이스 셋이다.

Data-Flow Testing
데이터-흐름 테스트는 데이터의 사용이 제어 흐름 만큼이나 오류에 취약하다는 아이디어에 기반한다. 데이터는 아래의 세 상태 중 하나를 가진다.
| 상태명 | 설명 |
|---|---|
| Defined | 초기화는 됐지만 쓰이고 있지는 않음 |
| Used | 계산을 위해 쓰이고 있는 상태 |
| Killed | 데이터가 어떤 방식으로 undefined된 상태.(할당 해제 등) |
추가적으로 다음과 같은 용어를 사용한다.
- Entered: 제어 흐름이 루틴에 진입한 후, 변수에 작업이 수행되기 전의 상태
- Exited: 변수에 작업이 수행된 직후, 제어 흐름이 루틴을 빠져나갈 때의 상태
Combinations of Data States
정상적으로는 데이터 상태가 Defined -> Used -> Killed의 순서로 변하는 것이 좋다. 아래는 비정상적 데이터 상태 패턴들이다.
| 조합 | 설명 | 문제점 |
|---|---|---|
| Defined-Defined | 변수를 두 번 정의 | 불필요한 중복 정의. 비효율적. 오류 가능성. |
| Defined-Exited | 정의 후 사용하지 않고 루틴을 종료 | 로컬 변수일 경우 의미 없음. 전역 변수는 예외 |
| Defined-Killed | 정의 후 사용하지 않고 바로 제거 | 불필요한 변수거나, 변수를 사용하는 코드가 누락 |
| Entered-Killed | 루틴 진입 직후 변수를 정의 또는 사용 없이 제거 | 로컬 변수일 경우 문제. (전역 변수는 예외) |
| Entered-Used | 루틴 진입 직후 변수를 정의하지 않고 사용 | 로컬 변수일 경우 오류. (전역 변수는 정의 확인 필요) |
| Killed-Killed | 제거된 변수를 재제거 | 이중 해제. 심각한 오류 가능성. |
| Killed-Used | 제거된 변수를 사용 | 논리적 오류. 우연히 제대로 동작할 수는 있음. |
| Used-Defined | 정의 전에 사용 | 이전에 정의됐는지에 따라 정상 작동할 수도 있고 그렇지 않을 수도 있음. 확인 필요. |
테스트를 시작하기 전에, 위와 같은 비정상적 데이터 상태 시퀀스가 있지는 않은지를 확인하도록 하자. 데이터-흐름 테스트 케이스 작성의 핵심은 가능한 모든 Defined-Used 경로를 실행하는 것.
- 모든 정의 확인: 변수가 값을 받는 모든 곳에서 변수 정의를 확인. 약함. 모든 라인 실행 시 이 작업은 자동으로 수행되기 때문.
- 모든 정의-사용 조합 확인: 한 곳에서 정의하고 다른 곳에서 사용하는 모든 조합을 테스트. 강함. 코드의 모든 라인을 실행한다고 해서 모든 정의-사용 조합이 테스트됐음을 보장하지는 않음.
//Java Example of a Program Whose Data Flow Is to Be Tested
if (Condition 1) x = a;
else x = b;
if (Cnodition 2) y = x + 1;
else y = x - 1;
- Structured basis test의 경우, $Condition 1= True, Condition 2 = True$인 TC와 $Condition1 = False, Condition2 = False$인 TC, 총 2개의 TC가 필요하다.
- 모든 Defined-Used 조합을 커버하는 경우에는 $Condition1 \times Condition2$, 총 4개의 TC가 필요하다.
Structured basis test에서 시작해, 전체 Defined-Used 데이터-흐름 TC를 확인할 수 있도록 TC를 추가하자. 앞서의 6개 TC 예제의 경우, 다음의 TC들을 추가할 수 있다.

데이터 흐름 TC를 몇 번 리스팅해보면, 어떤 게 추가돼야 하는지에 대한 감각을 키울 수 있는데, 만약 그래도 헷갈린다면 모든 Defined-Used 조합을 리스팅해보도록 하자.
Equivalence Partitioning
좋은 TC는 가능한 인풋 데이터의 많은 부분들을 커버한다. 정확히 같은 에러를 찾아내는 TC가 여러 개 있을 필요는 없다. 동등 분할(Equivalence Partitioning)은 이러한 아이디어를 바탕으로 필요한 TC의 수를 줄이는 방법이다.
앞서 봤던 긴 코드의 m_employee[ ID ].governmentRetirementWithheld < MAX_GOVT_RETIREMENT를 보자. 이 조건문의 동등 클래스는 다음의 둘 밖에 없다.
m_employee[ ID ].governmentRetirementWithheld < MAX_GOVT_RETIREMENTm_employee[ ID ].governmentRetirementWithheld >= MAX_GOVT_RETIREMENT
m_employee[ ID ].governmentRetirementWithheld의 값으로 가능한 것들은 여러가지가 있겠지만, 테스트를 위해서는 MAX_GOVT_RETIREMENT보다 큰 값 하나, 그것보다 작거나 같은 값 하나만 있으면 된다.
Error Guessing
정형화된 테스트 테크닉과 더불어, 좋은 프로그래머들은 휴리스틱한 테크닉도 많이 사용한다. 그런 테크닉 중 하나가 오류 추측(Error guessing)으로, 프로그램이 어디서 에러를 일으킬지를 추측하고, 이를 바탕으로 테스트 케이스를 작성하는 것이다.
Boundary Analysis
범위 조건이 주어진 경우, 해당 조건에 대한 테스트 케이스들을 작성하자. 예를 들어 가능한 최댓값이 주어진 경우,
- 최댓값보다 작은 값
- 최댓값
- 최댓값보다 큰 값
의 세 경우에 대한 테스트가 가능하다.

둘 이상의 변수가 상호 작용해 경계 조건을 만드는 경우도 염두에 두자. 변수 간 관계에 따라 조건이 복잡해질 수 있으므로, 더 섬세하고 다양한 테스트가 필요하다.


Classes of Bad Data
이외에도 여러 잘못된 데이터에 대한 추측과 테스트도 가능하다. 대표적으로는 다음의 것들이 있다.
- 너무 적거나 없는 데이터
- 너무 많은 데이터
- 잘못된 종류의 데이터
- 잘못된 크기의 데이터
- 초기화되지 않은 데이터

Classes of Good Data
잘 작동하는 데이터를 사용하는 정상적인 경우에도 오류가 발생할 수 있으니 확인해야 한다.
- 예상되는 중간값을 사용하는 테스트: 가장 자주 발생하는 상황
- 최소 정상 구성: 일반적으로 예상되는 값의 집합에서 최솟값을 만들어냄

- 최대 정상 구성

- 오래된 데이터와의 호환성: 오래된 프로그램/루틴을 대체하는 경우, 새 루틴이 같은 결과를 내는지에 대한 검증이 필요
Use Test Cases That Make Hand-Checks Convenient
테스트 케이스를 사용할 때에는, 그 결과를 직관적으로 알아보기 쉬운 것을 사용하는 게 좋다. 복잡한 TC가 오류를 더 잘 드러낼 것이라 생각할 수도 있지만, 그렇지만은 않다.
22.4 Typical Errors
Which Classes Contain the Most Errors?
보통 소스 코드 전반에 결함이 균등하게 흩어져있을 것이라 생각하곤 하지만, 사실 대부분의 오류는 결함이 많은 일부 루틴들에 집중되어 있다.
- 80%의 에러가 전체 프로젝트의 클래스/루틴의 20%에서 발견됨(Endres 1975, Gremillion 1984, Boehm 1987b, Shull et al 2002).
- 50%의 에러가 프로젝트 클래스의 5%에서 발견됨(Jones 2000).
위 조사 결과가 크게 중요하게 보이지 않을 수도 있다. 하지만
- 프로젝트 루틴의 20%가 개발 비용의 80%를 차지한다(결함이 꼭 개발 비용과 직결되는 것은 아니긴 하지만).
- 고-결함 루틴이 실제로 얼마나 많은 비용을 차지하는지와 상관없이, 고-결함 루틴은 그 자체로 많은 비용을 차지한다.
- 60년대의 연구에 따르면, 오류에 취약한 루틴들은 프로그램에서 가장 비싼 엔티티들에서 발견됐다.
- 코드 1000줄마다 50개의 결함이 발견됐고, 이것들을 수정하는 데에만 전체 프로그램을 개발하는 비용의 10배가 들었다.
- 문제를 일으키는 루틴을 피함으로써 비용의 약 80%를 절감할 수 있다면, 전체 개발 일정도 상당한 수준으로 단축시킬 수 있다.
- 문제를 일으키는 루틴을 피하는 것이 유지보수에도 도움을 준다.
- 유지보수 활동은 오류가 자주 발생하는 루틴을 식별하고, 재설계하고, 재작성하는 데 집중해야 한다.
Errors by Classification
여러 연구자들은 오류를 유형별로 분류하고, 각 유형의 오류가 발생하는 정도를 규명하려고 했다. 보리스 베이저(Boris Beizer)의 1990년 연구 결과를 요약하면 다음과 같다.
- 25.18% 구조적 오류
- 22.44% 데이터 오류
- 16.19% 구현된 기능 오류
- 9.88% 구현 과정의 오류
- 8.98% 통합 오류
- 8.12% 기능 요구사항 오류
- 2.76% 테스트 정의 또는 실행 오류
- 1.74% 시스템 및 소프트웨어 아키텍처 오류
- 4.71% 미분류
단 서로 다른 연구들이 다양한 종류의 오류를 보고하고 있고, 비슷한 유형의 오류를 다룬 연구에서도 결과가 크게 다르기 때문에, 여러 연구 결과를 결합한다고 해서 의미 있는 데이터가 산출되지는 않을 수도 있다. 다만 결과 데이터가 결정적이지 않기는 하지만, 몇 가지 시사하는 점이 있기는 하다.
- 대부분의 오류는 범위가 상당히 제한적이다.
- 한 연구에 따르면 85%의 오류는 한 루틴만 수정해도 해결할 수 있었다.
- 많은 오류는 구현 단계 밖에서 발생한다.
- 가장 흔한 오류의 원인 세 가지는, (1) 부족한 응용 분야 지식, (2) 변동하고 상충하는 요구 사항, (3) 의사소통 및 협업 실패
- 대부분의 구현 오류는 프로그래머의 잘못이다.
- 95%의 오류는 프로그래머, 2%는 시스템 소프트웨어, 2%는 다른 소프트웨어, 1%는 하드웨어에 의해 발생
- 오타가 문제의 원인인 경우가 상당히 많다.
- 디자인에 대한 잘못된 이해도 잦다.
- 디자인 이해는 즉각적인 성과를 내지 못하는 것처럼 보일 수도 있지만, 시간을 투자할 만하다.
- 대부분의 오류는 쉽게 고칠 수 있다.
- 85%의 오류는 수 시간 내에 수정할 수 있고, 나머지는 수 시간에서 며칠이 걸린다. 약 1%는 더 오래도 걸린다.
- 전체 오류의 20%를 수정하는 데 전체 자원의 80%가 쓰인다. 어려운 오류는 가능한 한 피하고, 많은 작은 오류는 효율적으로 처리하기.
- 조직 내에서 발생하는 오류 경험을 측정하는 것이 좋다.
- 조직이 다르면 경험도 달라 이해하기 힘들어진다.
- 개발 프로세스를 측정하고, 문제가 있는 곳을 파악하기.
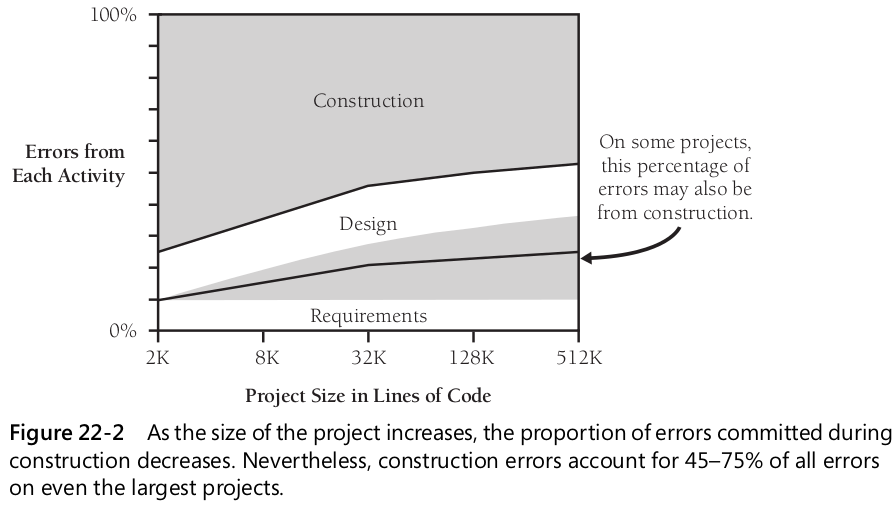
Proportion of Errors Resulting from Faulty Construction
상당수의 오류는 구현 과정에서 발생한다.
- 소규모 프로젝트에서는 구현 결함이 모든 오류의 대부분을 차지한다.
- 연구) 75% 코딩, 10% 요구사항, 15% 설계
- 프로젝트의 크기와 상관 없이, 구현 결함은 전체 결함의 최소 35%를 차지한다.
- 대규모 프로젝트의 경우 구현 결함의 비율이 더 낮기는 하지만, 그럼에도 여전히 전체 결함의 최소 35%는 차지한다.
- 일반적으로 응용 분야에 대한 이해가 높을수록 전체 아키텍처는 더 우수해지고, 오류는 상세 설계와 코딩에 집중되는 경향이 있다.
- 구현 오류는 요구사항 및 설계 오류보다는 저렴하지만, 여전히 비싸다.
- 연구) 평균적으로는 평균적인 설계 오류를 수정할 때의 25-25% 정도
- 하지만 구현 결함이 더 많아지면, 수정하는 데 드는 총 비용이 설계 결함을 수정하는 비용의 1-2배까지도 감
How Many Errors Should You Expect to Find?
사용하는 개발 프로세스의 퀄리티에 따라 발견할 것으로 예상되는 오류의 수도 바뀐다.
- 업계 평균: 1000줄 당 1-25에러.
- 여러 기법을 섞어 개발됨.
- 마이크로소프트 애플리케이션 부서: 사내 테스트에서는 1000줄 당 10-20개의 결함이 발견되고, 출시된 제품에서는 1000줄 당 0.5개.
- 코드 읽기 테크닉 및 독립 테스트의 결과
- 클린룸 개발 기법: 개발 중 1000줄 당 3개, 출시된 제품에서는 1000줄 당 0.1개.
- 일부 프로젝트(우주 왕복선 소프트웨어 등)에서는 형식적 개발 방법, 피어 리뷰, 통계적 테스트 등을 활용해 50만 줄의 코데에서 0개의 결함
- 팀 소프트웨어 프로세스(TSP): 1000줄 당 0.06개의 결함
- 개발자가 처음부터 결함을 만들지 않도록 교육하는 데에 중점을 둠
품질이 낮은 소프트웨어를 만들고 수정하는 것보다 처음부터 고품질 소프트웨어를 만드는 것이 낫다.
- 완전히 검증된 8만 줄 클린룸 프로젝트의 경우, 월당 740줄의 생산성
- 업계 평균의 경우, 월당 250-300줄의 생산성.
- TSP나 클린룸 프로젝트에서는 사실 디버깅에 거의 시간을 들이지 않기 때문에 비용이 절감되고 생산성이 향상됨.
Errors in Testing Itself
테스트 중인 코드만큼이나 테스트 케이스에도 오류가 있을 가능성이 높다. 특히 개발자가 테스트 케이스를 작성하는 경우에는 더욱 그렇다. 테스트 케이스는 종종 신중한 설계 및 작성 과정을 거치기보다 즉흥적으로 만들어지곤 한다. 이러한 TC는 일회성으로, 버릴 것을 전제로 개발해야 한다.
- 작업 확인하기
- 코드 작성만큼이나 신중하게 TC를 개발할 것. TC에 대한 워크-스루/인스펙션도 좋다.
- 소프트웨어를 개발하면서 TC 계획하기
- 효과적인 테스트 계획은 요구사항 단계나 프로그램에서의 작업을 맡은 즉시 시작해야 함
- TC 보관하기
- TC 품질에 더 투자하고, 회귀 테스트 및 이후 버전의 작업을 위해 보관하기.
- 나중에 TC를 사용할 계획을 갖고 시간을 들여 작업하는 것이 좋다.
- 단위 테스트를 테스트 프레임워크에 연결하기
- 단위 테스트 코드를 작성하되, 각 테스트를 완료할 떄마다 시스템의 전체 테스트 프레임워크에 통합하기.
- 통합된 테스트 프레임워크가 있으면, TC를 버리려는 경향을 막을 수 있다.
22.5 Test-Support Tools
Building Scaffolding to Test Individual Classes
비계(Scaffolding)라는 말은 건축에서 유래한 것으로, 작업자가 다른 방법으로는 접근할 수 없는 건물의 부분에 도달할 수 있도록 만들어진 구조물을 말한다. 소프트웨어의 비계는 코드 실행을 쉽게 하기 위해 특별히 만든 것을 말한다.
- 모의 객체(Mock object) 또는 스텁 객체(Stub object)
- 테스트 중인 다른 클래스에서 사용할 수 있도록 임시로 만들어진 클래스
- 비슷하게 스텁 루틴도 있다.
- 현실성 및 유사성을 더하거나 더는 데 쓰인다.
- 다음과 같은 기능들을 수행할 수 있다.
- 아무 작업도 수행지 않고 즉시 제어를 반환
- 입력된 데이터 검사
- 입력 매개변수를 출력하거나 파일에 메시지를 기록
- 대화형 입력으로부터 반환 값 얻기
- 입력과 관계없이 일정한 응답을 반환
- 실제 개체나 루틴에서 사용될 만큼의 클록 사이클 소모
- 실제 객체나 루틴보다 느리고/비효율적이게/단순하게/덜 정확하게 동작
- 드라이버(Driver), 또는 테스트 하네스(Test harness)
- 테스트할 실제 루틴을 호출하는 가짜 루틴
- 다음의 작업을 수행
- 고정된 입력값으로 객체를 호출
- 대화형으로 입력을 받고, 이를 사용해 객체를 호출
- 커맨드 라인에서 인자를 받아 객체를 호출
- 파일에서 인자를 받아 객체 호출
- 여러 번의 호출을 통해, 미리 정의된 입력 데이터들을 처리
- 더미 파일(Dummy files)
- 전체 크기 파일과 같은 타입을 가지고 있는, 작은 파일
- 파일이 작아 내용을 완전히 파악할 수 있고, 파일 자체에 오류가 없음을 합리적으로 확신할 수 있음
- 테스트를 위한 용도이므로, 사용 시 발생하는 오류를 눈에 띄게 설계할 수 있음
비계를 구축하는 것도 쉬운 일은 아니지만, 일단 만들어 놓으면 재사용할 수도 있고, 비계를 빠르게 생성할 수 있도록 돕는 도구들도 많다. 비계를 이용하면 다른 코드에 포함된 코드를 수 분의 시간을 들여 테스트할 수 있고, 디버깅에 소요되는 수 시간을 줄일 수 있다.
비계 사용을 위한 다양한 테스트 프레임워크들이 있으니 사용하도록 하자. 코드 통합 시에는 비계를 제거하기보다는 나중에 필요하면 쓸 수 있도록 전처리기 명령이나 주석을 통해 비활성화하는 것이 좋다.
Diff Tools
실제 출력과 예상 출력을 자동으로 비교할 수 있도록 하는 툴들을 사용하면 편하다.
Test-Data Generators
- 적절하게 설계된 랜덤 데이터 생성기를 이용하면 생각지 못한 특이한 테스트 데이터를 생성할 수 있다.
- 랜덤 데이터 생성기는 사람보다 더 철저하게 프로그램을 실행할 수 있다.
- 랜덤하게 생성된 TC는 시간에 따라 현실적인 입력 범위에 맞게 조정할 수 있다
- 모듈화된 설계는 테스트 시에 큰 도움이 된다.
- 다양한 조건에 따른 TC 생성이 가능해진다
- 테스트 드라이버는 코드가 변경되더라도 재사용할 수 있다.
Coverage Monitors
코드 커버리지를 제대로 측정하지 않는 경우 50-60%의 코드 밖에 제대로 실행하지 못한다. 커버리지 모니터는 실행된 코드와 실행되지 않은 코드를 추적하는 툴로, TC 집합이 코드를 완전히 실행하는지의 여부를 알려주기에 체계적인 테스트에 특히 유용하다. 많은 TC를 실행해도 커버리지 모니터가 아직 일부 코드가 실행되지 않고 있다고 한다면, 더 많은 테스트가 필요하다는 의미다.
Data Recorder/Logging
프로그램을 모니터링하고, 오류 발생 시 프로그램의 상태에 대한 정보를 수집하는 데 쓰인다. 중요한 이벤트는 파일에 기록하고, 오류가 발생하기 전의 시스템 상태 및 정확한 오류 조건들에 대한 세부 정보도 기록하자.
개발 버전/출시 버전에 따라 컴파일 대상으로 할지 그렇지 않을지 결정할 수도 있다.
Symbolic Debuggers
디버거를 이용하면 코드를 한 줄씩 실행하고, 변수의 값을 추적하며, 컴퓨터가 코드를 해석하는 방식과 똑같이 해석할 수 있다. 뿐만 아니라 디버거를 잘 이용하면 이미 발견된 오류를 진단하는 것 이상의 이점도 얻을 수 있다.
- 고급-언어 코드가 어떻게 어셈블리로 변환되는지의 과정을 확인할 수 있다.
- 레지스터 & 스택 모니터링을 통해 인자가 어떻게 전달되는지 확인할 수 있다.
- 컴파일러가 최적화한 코드를 보고, 어떤 최적화 과정이 수행됐는지 분석할 수 있다.
System Perturbers
예상치 못한 시스템 상 오류(ex. 초기화되지 않은 변수)를 찾아내기 위해 쓰이는 도구다.
- 메모리 채우기
- 초기화되지 않은 변수가 있는지 확인.
- ex) x86 프로세서에서 Interrupt 명령어에 해당하는 0xCC로 메모리를 채우고 코드를 실행하면 중단점이 발생해 오류를 탐지할 수 있음
- 메모리 재배열
- 프로그램이 실행되는 동안 메모리를 재배열해, 상대 위치가 아닌 절대 위치를 쓰는 코드인지를 확인할 수 있음
- 선택적 메모리 실패
- 메모리 요청을 실패시키거나, 실패하기 전에 임의의 메모리 요청을 허용하거나, 임의의 요청 후 하나만 허용하도록 설정할 수 있음
- 동적으로 할당된 메모리로 작업하는 복잡한 프로그램을 테스트할 때 특히 유용
- 메모리 접근 검사
- 포인터 작업을 감시해, 포인터가 올바르게 동작하는지 확인.
- 초기화되지 않은 포인터나 댕글링 포인터를 탐지하는 데 유용
Error Database
- 반복되는 오류를 확인.
- 새 오류가 발견되고 수정되는 속도를 추적
- 열린 오류/닫힌 오류의 상태 및 그 심각도를 추적할 수 있음
22.6 Improving Your Testing
Planning to Test
프로젝트의 시작부터 테스트를 계획하는 것이 좋다. 설계나 코딩과 같은 수준에 테스트를 두고, 일정한 시간을 할당하도록 하자.
Retesting (Regression Testing)
제품에 수정이 생기면 이전에 통과했던 테스트를 재수행해야 한다. 수정이 있을 때마다 다른 테스트를 실행하면, 어떤 새로운 결함이 생겼는지 제대로 알기 어렵다.
Automated Testing
같은 테스트를 여러 번 실행하고, 같은 결과를 여러 번 보면 둔감해지기 쉽다. 테스트를 자동화하면 회귀 테스트를 효과적으로 관리할 수 있다.
- 자동 테스트는 수동 테스트보다 오류가 발생할 가능성이 낮다.
- 한 번 테스트를 자동화하면, 나머지 프로젝트에서는 쉽게 재사용할 수 있다.
- 문제를 최대한 빠르게 탐지할 확률을 높인다.
- 대규모 코드 변경에 대한 안전망을 제공하며, 수정 중에 삽입된 결함을 빠르게 탐지할 가능성을 높여준다.
- 변동이 큰 기술 환경에서 특히 유용하다
22.7 Keeping Test Records
프로젝트의 테스트 결과를 측정하고 보관하면, 프로젝트의 변화가 업그레이드인지, 디그레이드인지를 쉽게 알 수 있다. 아래는 프로젝트 측정을 위해 모을 수 있는 데이터의 종류 예들이다.
- 결함에 대한 관리적 설명 (보고일, 보고자, 제목과 설명, 빌드 번호, 수정 날짜)
- 문제에 대한 전체 설명
- 문제를 반복하기 위한 단계
- 문제에 대해 제안된 우회 방법
- 관련된 결함
- 문제의 심각도
- 결함의 원인: 요구사항, 설계, 코드, 또는 테스트
- 코드 결함의 세분화: 오프 바이 원, 잘못된 할당, 잘못된 배열 인덱스, 잘못된 루틴 호출 등
- 변경된 클래스 및 루틴
- 결함에 영향을 받은 라인 수
- 결함을 찾는 데 걸린 시간
- 결함을 수정하는 데 걸린 시간
위와 같은 데이터들을 수집하면 여러 종류의 통계를 통해 프로젝트가 나아지고 있는지, 나빠지고 있는지를 파악할 수 있다.
- 각 클래스별 결함 수. 최악의 클래스 순위. 클래스 크기에 따른 정규화
- 각 루틴별 결함 수. 최악의 루틴 순위, 루틴 크기에 따른 정규화
- 결함 당 평균 테스트 시간
- TC 당 발견된 평균 결함 수
- 결함 수정 당 걸린 평균 시간
- TC로 커버된 코드 비율
- 각 심각도 별로 남아있는 결함 수
Personal Test Records
프로젝트 수준의 테스트 기록과 더불어, 자기 자신에 대한 테스트 기록을 추적하는 것도 유용하다. 내가 어떤 오류를 자주 일으키는지, 코드를 쓰고, 테스트하고, 오류를 고치는 데에는 얼마나 많은 시간을 쓸 수 있는지 등을 확인할 수 있다.
