24장 - 리팩토링
Edited by / (frog-slayer)

- 소프트웨어 개발에 대한 오해
- 요구사항 정의 및 설계가 진행된 후 코딩은 선형적으로 진행되며, 대부분의 코드는 작성 후 테스트가 끝나면 더 이상 수정할 필요가 없다.
- 코드의 주요 수정은 시스템의 최초 배포 후, 유지보수 단계에서만 이루어진다.
- 실제 소프트웨어 개발
- 초기 개발 단계에서도 코드는 많이 변한다.
- 코딩, 디버깅, 단위 테스트는 프로젝트의 규모에 따라 전체 노력의 30~65%를 차지한다.
- 잘 관리된 프로젝트에서도 요구사항이 매월 1~4% 씩 변하고, 이는 곧 코드 변경으로 이어진다.
- 과거 개발 방식은 코드 변경을 최소화하는 데 중점을 두었으나, 현대적 개발 방법론은 구현 중 코드 변경에 열려 있어, 프로젝트의 전 라이프 사이클 동안 코드가 지속적으로 변화하는 것을 수용한다.
24.1 Kinds of Software Evolution
(1) 진화 vs 퇴행
생물학적 진화와 유사하게 소프트웨어 진화에도 이로운 변이와 해로운 변이가 있을 수 있다. 이로운 변이의 경우, 변경을 기존 프로그램 설계의 개선 기회로 삼아 소프트웨어의 품질을 상승시킨다. 이와 달리 해로운 변이의 경우, 임시 방편적이고 미신적으로 문제를 해결해 소프트웨어의 품질을 하락시킨다.
(2) 개발(construction) 단계의 진화 vs 유지보수 단계의 진화
개발과 유지보수 중 어느 단계에서 진화가 일어나는지에 따른 구분도 중요하다. 개발 단계의 경우, 프로그램이 완성되기 전, 주로 원래의 개발자가 코드 변경을 수행한다. 아직 시스템이 운영 중인 상태가 아니므로 일정이 가장 큰 압박이 되고, 실수를 했을 때의 페널티도 적고, 자유롭고 유연하게 여러 새로운 시도를 해볼 수도 있다.
Philosophy of Software Evolution
보통 프로그래머들은 소프트웨어 진화를 의식적인 과정으로 생각하지 않는다. 하지만 소프트웨어 진화가 불가피하고 중요하다는 것을 깨닫고, 이에 대해 대비한다면 많은 이점을 누릴 수 있을 것이다.
소프트웨어 진화는 위험할 수도 있지만, 개선 기회가 되기도 한다. 항상 이후에 일어날 수 있는 변화들을 염두에 두고, 변경이 필요한 경우에는 이후 변화가 용이해지도록 코드를 개선하는 데에 노력해야 한다.
소프트웨어 진화의 기본 원칙(The Cardinal Rule of Software Evolution)
소프트웨어 진화는 항상 프로그램의 내적 품질을 개선시키는 방향으로 이루어져야 한다.
| 내적 품질 | 외적 품질 | |
|---|---|---|
| 관심사 | 사용자 관점에서 소프트웨어가 정확하게 작동하고 사용하기 쉬운지 | 개발자 관점에서 소프트웨어가 읽고 변경하기 쉬운지, 구조가 좋은지 |
| 예 | 정확성, 사용성, 효율성, 신뢰성, 무결성, 적응성, 정밀성, 견고성, … | 유지보수성, 유연성, 이식성, 재사용성, 가독성, 테스트 용이성, 이해 용이성, … |
24.2 Introduction to Refactoring
리팩토링(Refactoring)
소프트웨어의 관찰 가능한 행동은 변화시키지 않으면서 내적 구조를 수정해, 좀 더 이해하기 쉽고 수정에 용이하도록 만드는 것.
- 팩토링(factoring): 구조적 프로그래밍에서, 프로그램을 최대한 나눌 수 있는 만큼 부분 구성 요소로 나누는 것.
Reasons to Refactor
- 코드 중복
- 같은 것을 여러 군데에서 수정해야하게 될 수 있다.
- 루틴이 너무 긺
- OOP에서 스크린 하나를 넘어가는 루틴이 필요한 경우는 거의 없다. 그런 경우 보통은 구조적 프로그래밍을 OOP에 끼워 맞춰서 그런 경우가 많다.
- 시스템을 개선할 때는 모듈성을 높이는 것이 좋다.
- 너무 긴 루틴은 잘 정의된, 잘 명명된, 하나의 일만을 제대로 하는 여러 개의 루틴으로 나누는 것이 좋다.
- 루프가 너무 길거나, 너무 깊게 중첩됨
- 루프 내부를 별도의 루틴으로 분리해내면 루프의 복잡성을 줄이는 데 도움이 될 수 있다.
- 클래스의 응집도가 낮음
- 클래스가 상관성이 떨어지는 여러 책임을 가지는 경우, 복수의 클래스로 나누는 것이 좋다.
- 클래스 인터페이스가 일관적인 추상화 수준을 제공하지 않음
- 처음에는 클래스 인터페이스가 일관적인 추상화 수준을 가지고 있었더라도, 수정을 계속하다보면 클래스 인터페이스의 추상화 수준이 달라질 수도 있으니 주의.
- 파라미터 리스트의 파라미터가 너무 많음
- 긴 파라미터 리스트는 루틴 인터페이스 추상화가 제대로 되지 않았다는 경고일 수 있다.
- 클래스 내 변화가 구획화될 수 있음
- 때로는 한 클래스가 하나 이상의 서로 다른 책임을 가지는 경우가 있을 수 있다.
- 클래스의 한 부분이나 다른 부분을 수정하되, 여러 부분을 함께 수정하는 경우는 많지 않다면 해당 클래스를 더 작은 여러 클래스로 나눌 필요가 있을 수도 있다.
- 여러 클래스의 병렬 수정
- 변경마다 동일한 여러 클래스의 병렬 수정이 필요한 경우, 해당 클래스들의 코드를 재배치해, 하나의 변경이 하나의 클래스에만 영향을 주도록 할 수 있다.
- 상속 계층의 병렬 수정
- 한 클래스의 서브 클래스를 만들 때마다 다른 클래스의 서브클래스도 함께 만들어야 하는 경우
case문의 병렬 수정case자체가 나쁜 건 아니지만, 비슷한case문을 여러 곳에서 병렬적으로 수정해야 한다면, 상속을 이용해서 한 번에 처리하는 것도 고려할 것.
- 자주 함께 쓰이는 관련 데이터들을 클래스로 묶지 않은 경우
- 서로 연관된 데이터들이 여러 곳에서 반복적으로 함께 사용되는 경우, 이들을 하나의 클래스로 묶을 수 있을지 생각해보자.
- 루틴이 자신의 클래스보다 다른 클래스의 기능을 더 많이 사용하는 경우
- 루틴 이동이 필요할 수 있다.
- 원시 자료형을 과도하게 사용
- 어떤 정보를 표현하기 위해 원시 타입을 과도하게 사용하면 의미를 혼동할 위험이 커짐
- 의미 있는 도메인 객체(ex.
Money,Temperature등)를 만들어서 사용하면 컴파일러가 자료형을 확인해줄 수 있다.
- 클래스가 별로 하는 일이 없음
- 리팩토링 후, 별로 하는 일이 없어진 코드/클래스의 경우 삭제해도 되는지 검토할 것
- 루틴 체인이 트램프 데이터(tramp data)를 전달
- 트램프 데이터 자체가 나쁜 것은 아니지만, 추상화 수준이 일관적으로 유지되는지를 잘 확인해야 한다.
- 중간 객체가 아무 것도 하지 않음
- 다른 클래스의 메서드를 호출하는 역할만 하는 중간 객체의 경우, 해당 객체를 제거하고 호출하는 클래스를 직접 참조할 수 있는지 확인
- 한 클래스가 다른 클래스와 너무 가까움
- 한 클래스가 자신이 알아야 하는 것 이상으로 다른 클래스에 대해 알고 있는 경우(캡슐화가 지켜지지 않는 경우)를 확인
- 루틴의 이름이 구림
public데이터 멤버public데이터 멤버는 인터페이스/구현의 경계를 무너뜨리고, 캡슐화를 위반한다.public데이터 멤버를 직접 사용하기 보다는 접근 루틴을 사용하는 것을 고려
- 서브 클래스가 부모의 루틴 중 극히 일부만 사용
- 실제 상속 관계도 아니면서, 어떤 클래스의 루틴을 사용하기 위해 상속을 사용한 경우가 많음.
- 상속 관계를 제거하고, 부모 클래스를 멤버 변수로 포함시키는 방법을 사용할 수 있음.
- 주석으로 난해한 코드를 설명
- 주석으로 복잡한 로직을 설명하려는 시도는 품질 저하의 신호
- 나쁜 코드는 문서화하지 말고 고쳐라.
- 전역 변수 사용
- 루틴 호출 전후로 설정/정리 코드가 필요한 경우
- 항상 나쁜 건 아니지만, 추상화 수준이 제대로 유지되는지 확인할 것
//Bad C++ Example of Setup and Takedown Code for a Routine Call
WithdrawalTransaction withdrawal;
withdrawal.SetCustomerId( customerId );
withdrawal.SetBalance( balance );
withdrawal.SetWithdrawalAmount( withdrawalAmount );
withdrawal.SetWithdrawalDate( withdrawalDate );
ProcessWithdrawal( withdrawal );
customerId = withdrawal.GetCustomerId();
balance = withdrawal.GetBalance();
withdrawalAmount = withdrawal.GetWithdrawalAmount();
withdrawalDate = withdrawal.GetWithdrawalDate();
//Similar Bad C++ Example
withdrawal = new WithdrawalTransaction( customerId, balance,
withdrawalAmount, withdrawalDate );
withdrawal.ProcessWithdrawal();
delete withdrawal;
//Good C++ Example of a Routine That Doesn’t Require Setup or Takedown Code
ProcessWithdrawal( customerId, balance, withdrawalAmount, withdrawalDate );
//C++ Example of Code That Requires Several Method Calls (Bad)
//We have a WithdrawalTransaction object in hand
ProcessWithdrawal( withdrawal.GetCustomerId(), withdrawal.GetBalance(),
withdrawal.GetWithdrawalAmount(), withdrawal.GetWithdrawalDate() );
//Good Example
ProcessWithdrawal( withdrawal );
- 나중에 언젠가 쓰일 수도 있을 것 같은 코드를 미리 포함
- 요구사항이 완전히 정의되지 않은 상태에서 작성된 코드는 버려질 가능성이 큼
- 미래 요구사항의 복잡한 세부 내용을 미리 고려하기는 어려움
- 미래에 해당 코드를 사용하는 개발자들이 그 코드가 충분히 검증/테스트 되었다고 잘못 가정할 가능성이 높음
- 현재 필요하지 않은 코드가 추가되면서 복잡성이 증가함
- 현재 필요한 코드를 가능한 한 깔끔하고 직관적으로 쓰는 것이 훨씬 낫다.
Reasons Not to Refactor
흔히 리팩토링이라는 말을 결함 수정, 기능 추가, 디자인 수정 등 모든 코드 변경 작업을 의미하는 데 쓰기도 한다.
변화 그 자체가 좋은 게 아니라, 소프트웨어의 품질 저하를 방지하고 지속적인 개선을 이끌어낼 수 있는, 목적이 있는 변화인 것이 중요하다.
24.3 Specific Refactorings
Data-Level
- 매직 넘버를 이름 상수로 대체
- 변수명을 명확하고 정보를 주는 이름으로 재명명
- 불필요한 중간 변수를 사용하지 않고 식을 바로 사용
- 식의 의도를 더 잘 나타낼 수 있다면, 중간 변수를 사용하기
- 반복되는 식의 경우 별도의 루틴으로 분리
- 한 변수를 많이 사용하지 말고, 구체적인 용도와 이름이 있는 변수 여러 개를 한 번 씩 사용하기
- 입력 용도로만 쓰이는 파라미터가 루틴 내에서 쓰이는 경우, 파라미터 자체를 쓰지 말고 로컬 변수를 만들어서 사용하기
- 원시 자료형을 클래스로 변환
- 타입을 나타내는 코드는 클래스나 열거형으로 변환
- 각 타입에 따라 서로 다른 행동을 하는 경우 하나의 기본 클래스를 두고 타입에 따라 서브 클래스를 나눠 사용할 것
- 서로 다른 타입의 요소를 가진 배열의 경우, 배열보다는 클래스를 사용
- 컬렉션을 캡슐화
- 컬렉션을 반환하는 클래스의 경우, 그 자체를 반환하지 말고 읽기 전용 컬렉션을 반환
- 컬렉션을 직접 수정하지 않고, 요소를 추가/제거하는 메서드를 제공할 것
- 전통적인 레코드를 데이터 클래스로 변환
Statement-Level
- 복잡한 불리언 식의 경우, 의도를 잘 파악할 수 있는 이름의 중간 변수들을 두고 분할
- 복잡한 불리언 식을 잘-명명된 불리언 함수로 변경
if블럭 끝에서도,else블럭 끝에서도 나타나는 코드의 경우, 전체if-then-else블럭 밖으로 해당 코드를 이동- 루프 제어 변수를 조작하지 말고
break나return을 사용 - 중첩
if문의 경우, 답이 뭔지 알게 되는 즉시 반환 - 조건문을 다형성으로 교체 (특히 반복되는
case문의 경우) null값을 테스트하기보다는null객체를 생성해서 사용할 것
// Bad
class Customer {
private String name;
public Customer(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
public class Main {
public static void main(String[] args) {
Customer customer = new Customer(null);
String name = "Unknown";
if (customer.getName() != null) {
name = customer.getName();
}
System.out.println("Customer Name: " + name);
}
}
// Good
class Customer {
private String name;
public Customer(String name) {
if (name == null) {
this.name = "Occupant";
} else {
this.name = name;
}
}
public String getName() {
return name;
}
}
public class Main {
public static void main(String[] args) {
Customer customer = new Customer(null);
System.out.println("Customer Name: " + customer.getName());
}
}
Routine-Level
- 복잡한 루틴의 인라인 코드에서 루틴/메서드 추출하기
- 간단한 루틴의 경우, 해당 루틴을 사용하는 곳을 인라인으로 바꾸기
- 긴 루틴은 여러 짧은 루틴을 가지는 클래스로 변환
- 복잡한 알고리즘을 간단한 알고리즘으로 대체
- 루틴에 정보가 더 필요하다면 파라미터를 추가
- 파라미터를 사용하지 않는 경우 제거
- 쿼리와 수정을 구분
- 비슷한 루틴을 파라미터화해서 합치기
- 파라미터에 따라 동작이 달라지는 루틴 구분
- 구체적인 필드 대신 전체 객체를 전달
- 전체 객체 대신 구체적인 필드 전달
- 루틴이 객체를 반환하는 경우, 가장 구체적인 타입을 반환하도록 함.
Class Implementation
- 크고 복잡한 객체의 경우, 매번 복사해서 사용하기 보다는 참조 객체로 사용
- 작고 단순한 객체의 경우, 참조 객체보다 값 객체로 변경하는 게 좋을 수 있음
- 가상 루틴을 데이터 초기화로 교체
- 서브클래스들이 서로 다른 상수 값을 반환한다는 차이만 갖는 경우, 메서드 오버라이드 대신 상수 값 초기화 + 기본 클래스의 메서드를 이용
//메서드 오버라이드
class Vehicle {
public String getType() {
return "Unknown Vehicle";
}
}
class Car extends Vehicle {
@Override
public String getType() {
return "Car";
}
}
class Truck extends Vehicle {
@Override
public String getType() {
return "Truck";
}
}
// 데이터 초기화로 교체
class Vehicle {
private String type;
public Vehicle(String type) {
this.type = type;
}
public String getType() {
return type;
}
}
class Car extends Vehicle {
public Car() {
super("Car");
}
}
class Truck extends Vehicle {
public Truck() {
super("Truck");
}
}
- 상속 계층에서의 멤버 루틴 및 데이터 위치 변경
- 상속 클래스에서의 중복을 제거
- 루틴/필드/생성자를 상위 클래스로 올리기
- 루틴/필드/생성자를 하위 클래스로 내리기
- 특화된 코드는 추출해서 서브클래스로 넣기
- 여러 서브클래스가 비슷한 코드를 가지고 있는 경우, 해당 코드를 합쳐 상위 클래스로 올리기
Class Interface
- 루틴을 다른 클래스로 이동
- 여러 책임을 가지는 하나의 클래스를 서로 독립적인 클래스로 분리
- 클래스가 많은 일을 하지 않는 경우, 응집도가 높은 다른 클래스로 코드를 이동시키고 클래스를 삭제
- 위임 숨기기
- A가 B, C를 호출 <-> A가 B를 호출, B가 C를 호출
- 적절한 추상화 수준에 맞춰서 선택할 것
- 중간자 제거
- A -> B -> C로 호출하지 않고 A에서 직접 C를 호출하는 게 나은 경우가 있을 수도 있음
- 상속을 위임으로 대체
- 다른 클래스를 쓰기는 하되, 필요에 맞게 그 인터페이스를 제어하고 싶은 경우, 상속 대신 필드에 추가해 위임 클래스로 사용.
- 위임을 상속으로 대체
- 클래스가 위임 클래스의 모든
public루틴을 노출시키는 경우, 위임보다는 상속으로 바꾸기
- 클래스가 위임 클래스의 모든
- 외부 루틴 도입
- 추가적인 루틴이 필요하고, 해당 루틴을 제공하는 클래스를 변경할 수는 없는 경우, 해당 기능을 사용하는 쪽에 별도의 메서드를 추가
- 확장 클래스 도입
- 추가적인 루틴들이 필요하고, 해당 루틴을 제공하는 클래스를 변경할 수는 없는 경우, 해당 클래스를 상속하거나 필드로 가지는 클래스를 만들어서 사용
- 공개된 멤버 변수 캡슐화
public멤버 변수의 경우,private으로 변경하고 접근 루틴을 사용하기
- 변경할 수 없는 필드의 경우
Set()루틴을 제거 - 클래스 밖에서 사용될 루틴이 아니라면 숨기기
- 사용되지 않는 루틴 캡슐화
- 계속해서 인터페이스의 일부만을 사용한다면, 그 부분만을 노출시키는 새로운 인터페이스를 만들기
- 상위 클래스/하위 클래스의 구현이 매우 비슷한 경우 하나로 병합하기
System-Level
- 시스템에서 매번 직접 접근하기는 번거로운 데이터를 사용할 때, 해당 데이터를 참조하는 별도의 클래스 생성
- 단방향 클래스 연관을 양방향 클래스 연관으로 변경
- 양방향 클래스 연관을 단방향 클래스 연관으로 변경
- 생성자 대신 팩토리 메서드를 사용
- 에러 코드를 예외 등으로 수정
24.4 Refactoring Safely
- 초기 코드를 버전 관리 시스템에 저장하거나 백업하기
- 리팩토링은 작게 유지해서, 변경의 영향을 제대로 인지할 수 있도록 하기
- 한 번에 하나의 리팩토링만을 수행하고, 매 리팩토링마다 컴파일 및 테스트 수행하기
- 수행할 단계 목록화
- 리팩토링 중 추가적인 개선사항 발견 시, 나중에 처리할 수 있도록 기록
- 오류가 발생하거나 변경이 잘못되었을 때, 이전의 안정된 상태로 돌아갈 수 있도록 자주 체크포인트 만들기
- 컴파일러 경고 활용하기
- 리테스트
- 테스트 케이스 추가
- 변경 사항 리뷰
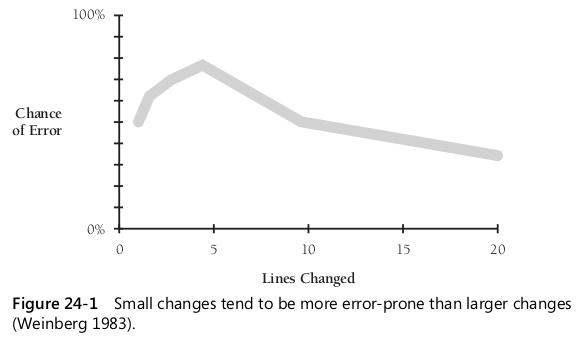
- 작은 변경은 제대로 확인하지 않아 오류가 일어날 확률이 더 높다.
- 리팩토링의 위험도에 따라 다른 접근 방식 사용하기
- 어떤 리팩토링은 다른 것보다 더 위험하다
- 예) 매직넘버를 이름 상수로 수정하는 것은 안전한 편이고, 클래스/루틴 인터페이스 수정, 데이터베이스 스키마 수정, 불리언 테스트 수정 등은 더 위험하다)
Bad Times to Refactor
- 리팩토링이 만병통치약은 아니다
- 잘못된 코드를 고치면서 리팩토링이라 하지 말기
- 대규모 변경이 필요한 경우, 기존 코드를 조금씩 고치는 것보다 처음부터 재설계/재작성하는 게 나을 수도 있다.
24.5 Refactoring Strategies
리팩토링에는 끝이 없지만, 효율을 고려하는 게 좋다. 리팩토링도 다른 프로그래밍 활동처럼 80/20의 법칙을 따르니, 무작정 리팩토링하기보다는 큰 개선 효과를 낼 수 있는 일부에 집중하도록 하자.
- 루틴 추가할 때, 관련 루틴들이 잘 정리되어 있는지 확인하고 리팩토링하기
- 새 클래스를 추가하면 기존 코드의 이슈가 드러날 수 있다. 새 클래스 추가를 리팩토링의 기회로 삼기
- 결함 수정 시 리팩토링
- 에러에 취약한 모듈 타게팅
- 높은 복잡도를 가지는 모듈 타게팅
- 유지보수 환경에서 건드리게 되는 코드는 항상 개선하기
- 절대로 수정되지 않는 코드는 리팩토링할 필요가 없지만, 기왕 건드릴 것이라면 꼭 개선하도록 하자
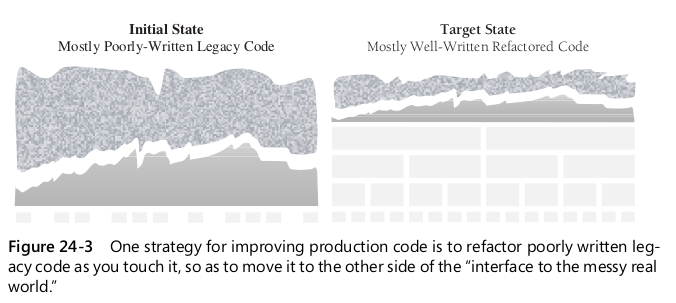
- 깨끗한 코드와 지저분한 레거시 코드 사이에 인터페이스를 정의하고 코드를 이동시키기